{
"cells": [
{
"cell_type": "markdown",
"id": "9e54c615-5dab-4642-924f-f2840558ff9e",
"metadata": {},
"source": [
"Peter Norvig
April 2026
\n",
"\n",
"# Did you solve it? R y clvr ngh t rd ths sntnc?\n",
"\n",
"Alex Bellos's [30 March 2026 column](https://www.theguardian.com/science/2026/mar/30/did-you-solve-it-r-y-clvr-ngh-t-rd-ths-sntnc) asks us to guess famous phrases or sayings, given the shapes of the rectangles that bound the letters, and the clue that vowels are **green** and consonants are **blue**. \n",
"\n",
"Here's one of the puzzles:\n",
"\n",
"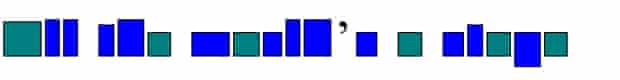"
]
},
{
"cell_type": "markdown",
"id": "6a2c1014-5894-4bf0-b4b3-5f1d1561fa2a",
"metadata": {},
"source": [
"I can help solve this problem by using code to constrain what each letter and each word might be.\n",
"\n",
"I'll start by defining different subsets of letters: `v` for the vowels, `c` for the consonants, `a` for the letters whose shape ascends above the norm, etc.:"
]
},
{
"cell_type": "code",
"execution_count": 24,
"id": "628d38c1-0671-49dd-9897-7bd5eff196ee",
"metadata": {},
"outputs": [],
"source": [
"letters = set('abcdefghijklmnopqrstuvwxyz')\n",
"v = set('aeiou') # vowels (green)\n",
"c = letters - v # consonants (blue)\n",
"\n",
"a = set('bdfhijlt') # ascending\n",
"d = set('gjpqy') # descending\n",
"b = letters - a - d # block: neither ascending nor descending\n",
"\n",
"t = set('li') # thin\n",
"w = set('mw') # wide\n",
"n = letters - t - w # normal: neither wide nor thin"
]
},
{
"cell_type": "markdown",
"id": "f51d68da-7569-4bdd-97a2-3c245e143c70",
"metadata": {},
"source": [
"Now I can say that the first letter of the first word above (the green rectangle) is a block-shaped vowel; the intersection of the **b**lock and **v**owel sets, denoted in Python with the `&` operator:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "1f17f9ce-0e88-464d-80e6-53a458b3594b",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'a', 'e', 'o', 'u'}"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"b&v"
]
},
{
"cell_type": "markdown",
"id": "de4886ea-0244-4582-8a43-9fae9daceb9a",
"metadata": {},
"source": [
"The first word has three letters, `b&v` followed by two **a**scending **t**hin **c**onsonants, `a&t&c`:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "df3a9acf-e4df-42eb-8eb0-61fbdda7b598",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[{'a', 'e', 'o', 'u'}, {'l'}, {'l'}]"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"[b&v, a&t&c, a&t&c]"
]
},
{
"cell_type": "markdown",
"id": "b3945fa3-587c-4155-b201-ed7aa55510e5",
"metadata": {},
"source": [
"Neat! There is only one **a**scending **t**hin **c**onsonant, `'l'`.\n",
"\n",
"The whole puzzle is as follows (I made the apostrophe be a word of its own):"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "b4b5bb61-08f6-4815-9f46-ff1dd8e5816c",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[[{'a', 'e', 'o', 'u'}, {'l'}, {'l'}],\n",
" [{'b', 'd', 'f', 'h', 'j', 'l', 't'},\n",
" {'b', 'd', 'f', 'h', 'j', 'l', 't'},\n",
" {'a', 'e', 'o', 'u'}],\n",
" [{'m', 'w'},\n",
" {'a', 'e', 'o', 'u'},\n",
" {'c', 'k', 'm', 'n', 'r', 's', 'v', 'w', 'x', 'z'},\n",
" {'b', 'd', 'f', 'h', 'j', 'l', 't'},\n",
" {'b', 'd', 'f', 'h', 'j', 'l', 't'}],\n",
" [{'’'}],\n",
" [{'c', 'k', 'm', 'n', 'r', 's', 'v', 'w', 'x', 'z'}],\n",
" [{'a', 'e', 'o', 'u'}],\n",
" [{'c', 'k', 'm', 'n', 'r', 's', 'v', 'w', 'x', 'z'},\n",
" {'b', 'd', 'f', 'h', 'j', 'l', 't'},\n",
" {'a', 'e', 'o', 'u'},\n",
" {'g', 'j', 'p', 'q', 'y'},\n",
" {'a', 'e', 'o', 'u'}]]"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"puzzle3 = [[b&v, a&t&c, a&t&c], [a&c, a&c, b&v], [w&c, b&v, b&c, a&c, a&c], [{\"’\"}], [b&c], [b&v], [b&c, a&c, b&v, d&c, b&v]]\n",
"puzzle3"
]
},
{
"cell_type": "markdown",
"id": "50586a9e-2a63-4c43-858e-509e783aa99f",
"metadata": {},
"source": [
"## Possible Words\n",
"\n",
"What combinations of letters can each word pattern make? The function `possible_words` goes through the pattern one letter set at a time and builds up all possible ways of adding each possible letter to each possible partial word string:"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "664292e4-416c-4408-bc9a-a5df0f2ede08",
"metadata": {},
"outputs": [],
"source": [
"def possible_words(pattern: list[set[str]]) -> set[str]:\n",
" \"\"\"All ways of choosing one letter from each of the possible letters in the word pattern.\"\"\"\n",
" words = {''} # To start there is one possible partial word, with no letters\n",
" for letter_set in pattern:\n",
" # On each turn, add each possible letter to each possible partial word\n",
" words = {word + letter for word in words for letter in letter_set}\n",
" return words"
]
},
{
"cell_type": "markdown",
"id": "c3de036e-7ca3-45f5-99ca-ead670ced8a0",
"metadata": {},
"source": [
"For example,"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "2743ba3a-0474-4f04-91cf-7ea57550b74c",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'all', 'ell', 'oll', 'ull'}"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"possible_words([b&v, a&t&c, a&t&c])"
]
},
{
"cell_type": "markdown",
"id": "d213da56-3d0b-4344-ab09-6a676b11a1f2",
"metadata": {},
"source": [
"Another example:"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "0a8cb3da-3d3d-4241-9d22-8b50c16aeb8d",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'ban', 'bat', 'bon', 'bot', 'can', 'cat', 'con', 'cot'}"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"possible_words([{'b', 'c'}, {'a', 'o'}, {'n', 't'}])"
]
},
{
"cell_type": "markdown",
"id": "799abea2-83a4-4d71-bd04-270ff056249a",
"metadata": {},
"source": [
"Let's trace through how `possible_words` works on this example. It starts with one possible partial word, the empty string:\n",
"\n",
" words = {''}\n",
"\n",
"Then it enterts the `for` loop and looks at the first letter set, `{'b', 'c'}`, and adds each letter to each partial word (just one of them: the empty string) to get a set of two partial words:\n",
"\n",
" words = {'b', 'c'}\n",
"\n",
"It does the same thing with the second letter set, `{'a', 'o'}`, to get a set of four partial words:\n",
"\n",
" words = {'ba', 'bo', 'ca', 'co'}\n",
"\n",
"Finally, it considers the third letter set, `{'n', 't'}`, and gets the final answer, a set of eight words:\n",
"\n",
" words = {'ban', 'bat', 'bon', 'bot', 'can', 'cat', 'con', 'cot'}\n",
"\n",
"## Dictionary Words\n",
"\n",
"What actual dictionary words could a pattern stand for? To answer that I'll need a list of actual dictionary words. Furthermore, when `possible_words(pattern)` returns more than one word, I'll have to pick one. To facilitate that, I will use a word list that includes the frequency of each word so that I can pick the word with the highest frequency. \n",
"\n",
"I'll download the word list file \"[count_big.txt](count_big.txt)\" which has the format: \n",
"\n",
" a 21160\n",
" aah 1\n",
" aaron 5\n",
" ab 2\n",
" aback 3\n",
" abacus 1\n",
" abandon 32\n",
" abandoned 72\n",
" abandoning 27\n",
" abandonment 15\n",
"\n",
"A few things to note about the following command (but you don't need to memorize):\n",
"- The `!` at the start of a line means to do an operating system command, not a Python command.\n",
"- The `[ -e count_big.txt ] ||` part says to skip downloading the file if it already exists.\n",
"- The `curl` command downloads the file\n"
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "4b0b245b-5085-492e-b3c3-902f2d8ae723",
"metadata": {},
"outputs": [],
"source": [
"! [ -e count_big.txt ] || curl -O https://norvig.com/ngrams/count_big.txt"
]
},
{
"cell_type": "markdown",
"id": "65006749-5475-434c-a6bb-aab8c81e6e0b",
"metadata": {},
"source": [
"I'll read the contents of the file into a Python dictionary, which will have the form `{'a': 21160, 'aah': 1, ...}`. "
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "c863b2e8-4e81-4c13-bd62-2aa7be38ad92",
"metadata": {},
"outputs": [],
"source": [
"def make_dictionary(lines) -> dict:\n",
" \"\"\"The lines are strings with a word and a frequency count; make it into a dict.\"\"\"\n",
" counts = {} # Start with an emoty dict\n",
" for line in lines:\n",
" word, count = line.split()\n",
" counts[word] = int(count)\n",
" return counts\n",
"\n",
"dictionary = make_dictionary(open('count_big.txt'))"
]
},
{
"cell_type": "markdown",
"id": "a5939c3b-b99a-4e8d-9cf5-9f4e8eb1533f",
"metadata": {},
"source": [
"Here are some things you can do with the dictionary:"
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "9edff66d-8668-4408-b636-a2aec0614fcb",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 10,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"'aback' in dictionary"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "cae82016-a5d1-4fac-9e4d-75029e506f67",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"'the' in dictionary"
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "8bf5eb96-7502-4568-bba0-71313f481e99",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 12,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"'xyzzy!@#$' in dictionary"
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "5cbaf8af-a4eb-4390-b0f2-0bb0e32426ca",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"80030"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"dictionary['the'] # get the frequency count"
]
},
{
"cell_type": "code",
"execution_count": 14,
"id": "d1919007-f2e6-484a-a078-c9dd805a17c2",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"80030"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"dictionary.get('the', 0) # Get the count, with a default of 0 if word is not in dictionary"
]
},
{
"cell_type": "code",
"execution_count": 23,
"id": "b137e272-9f34-4ecc-9131-934304a4f5b2",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"0"
]
},
"execution_count": 23,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"dictionary.get('xyzzy!@#$', 0) # Get the count, with a default of 0 if word is not in dictionary"
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "5e10a770-0945-48c7-ad37-826f2e42a2b1",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"29136"
]
},
"execution_count": 15,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"len(dictionary) # the number of words in the dictionary"
]
},
{
"cell_type": "markdown",
"id": "3662284a-b83e-4122-9896-831fc8580a87",
"metadata": {},
"source": [
"Now I want to take a pattern and figure out the most likely word (which I will guess is the most frequent one):"
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "fea1a704-ab79-4204-bd89-506e66c12042",
"metadata": {},
"outputs": [],
"source": [
"def most_likely_word(pattern: list[set[str]]) -> str:\n",
" \"\"\"Out of all the possible words the pattern can make, pick the most frequent one.\"\"\"\n",
" return max(possible_words(pattern), key=frequency)\n",
"\n",
"def frequency(word) -> int: \n",
" \"\"\"The frequency count of the word in the dictionary, or 0 by default.\"\"\"\n",
" return dictionary.get(word, 0) "
]
},
{
"cell_type": "code",
"execution_count": 17,
"id": "a7cbb472-ce03-4239-b64f-ee1f8cbe02e3",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'all'"
]
},
"execution_count": 17,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"most_likely_word([b&v, a&t&c, a&t&c])"
]
},
{
"cell_type": "markdown",
"id": "d78f5702-9064-4a50-822e-f6ad89a16497",
"metadata": {},
"source": [
"So far, so good!\n",
"\n",
"A puzzle consists of a list of word patterns, and we can generate a best guess at solving the puzzle by finding the `most_likely_word` for each word pattern, and then joining them into a big string."
]
},
{
"cell_type": "code",
"execution_count": 18,
"id": "b6f70f1d-5f16-4d80-bb95-fc8b01ab57df",
"metadata": {},
"outputs": [],
"source": [
"def solve(puzzle: list[list[set[str]]]) -> str:\n",
" \"\"\"Given a puzzle (a list of word patterns), return a string formed from the most likely matching words.\"\"\"\n",
" return ' '.join(most_likely_word(pattern) for pattern in puzzle)"
]
},
{
"cell_type": "markdown",
"id": "316692e0-244f-4715-bec9-f6e7babcd036",
"metadata": {},
"source": [
"## Puzzle #3\n",
"\n",
"We're ready to see if our program can solve the puzzle:\n",
"\n",
"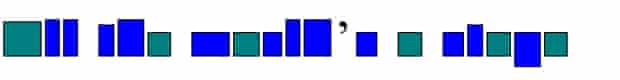\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": 19,
"id": "42054f45-a8af-4513-a5d0-f097b2acda02",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'all the world ’ s a stage'"
]
},
"execution_count": 19,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"solve(puzzle3) "
]
},
{
"cell_type": "markdown",
"id": "8e3b7a2a-259c-463f-b542-5c095c559516",
"metadata": {},
"source": [
"It worked! Let's do another one:\n",
"\n",
"## Puzzle #1\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": 20,
"id": "688d1a5c-2770-4dd1-b8db-5d535949f909",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'all ’ s well that ends well'"
]
},
"execution_count": 20,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"solve([[b&v, a&t&c, a&t&c], [{\"’\"}], [b&c], [w&c, b&v, t&c, t&c], [a&c, a&c, b&v, a&c], [b&v, b&c, a&c, b&c], [w&c, b&v, t&c, t&c]])"
]
},
{
"cell_type": "markdown",
"id": "47db30ff-a96a-47d7-a4a0-34fe29dad4db",
"metadata": {},
"source": [
"That's correct!\n",
"\n",
"## Puzzle #8\n",
"\n",
" "
]
},
{
"cell_type": "code",
"execution_count": 21,
"id": "599ece2f-88a2-4818-83f9-0d0e478986ab",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'all roads lead to some'"
]
},
"execution_count": 21,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"solve([[v, a&c, a&c], [b&n&c, b&n&v, b&n&v, a&c, b&c], [a&t&c, b&v, b&v, a&c],[a&c, b&v], [c, b&v, w&b&c, b&v]])"
]
},
{
"cell_type": "markdown",
"id": "bfd1dc29-5958-4c51-a124-b39d633ea60f",
"metadata": {},
"source": [
"OK, not quite right, but a good hint.\n",
"\n",
"One more:\n",
"\n",
"## Puzzle #10\n",
"\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": 22,
"id": "68d34678-7688-49c4-94b6-5ba207497866",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'have in blind'"
]
},
"execution_count": 22,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"solve([[a&c, b&v, b&c, b&v], [a&v, b&c], [a&c, a&t&c, a&v, b&c, a&c]])"
]
},
{
"cell_type": "markdown",
"id": "87eb56d5-9a6b-41f0-8eec-b4c8f63dbdbd",
"metadata": {},
"source": [
"That's not right either, but again it is a good clue to the right answer. (One reason I didn't get this one right is that I didn't consider capital letters, and a Capital \"L\" has a different shape than a lowercase \"l\".)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "747c3d08-c98a-497d-9430-f6a69dbd70cc",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python [conda env:base] *",
"language": "python",
"name": "conda-base-py"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.13.9"
}
},
"nbformat": 4,
"nbformat_minor": 5
}