Merge branch 'norvig:main' into master
This commit is contained in:
713
ipynb/ClimbingWall.ipynb
Normal file
713
ipynb/ClimbingWall.ipynb
Normal file
File diff suppressed because one or more lines are too long
File diff suppressed because it is too large
Load Diff
@@ -1122,7 +1122,7 @@
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"It is still surprising that we still have no efect from restricting trade."
|
||||
"It is still surprising that we still have no effect from restricting trade."
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
993
ipynb/KenKen.ipynb
Normal file
993
ipynb/KenKen.ipynb
Normal file
File diff suppressed because one or more lines are too long
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@@ -36,7 +36,7 @@
|
||||
" The set of all possible outcomes for the trial. \n",
|
||||
" <br>*For example,* `{1, 2, 3, 4, 5, 6}`.\n",
|
||||
"- **[Event](https://en.wikipedia.org/wiki/Event_(probability_theory%29):**\n",
|
||||
" A subset of outcomes that together have some property we are interested in.\n",
|
||||
" A subset of the sample space, a set of outcomes that together have some property we are interested in.\n",
|
||||
" <br>*For example, the event \"even die roll\" is the set of outcomes* `{2, 4, 6}`. \n",
|
||||
"- **[Probability](https://en.wikipedia.org/wiki/Probability_theory):**\n",
|
||||
" As Laplace said, the probability of an event with respect to a sample space is the \"number of favorable cases\" (outcomes from the sample space that are in the event) divided by the \"number of all the cases\" in the sample space (assuming \"nothing leads us to expect that any one of these cases should occur more than any other\"). Since this is a proper fraction, probability will always be a number between 0 (representing an impossible event) and 1 (representing a certain event).\n",
|
||||
@@ -2339,7 +2339,7 @@
|
||||
"def repeated_hist(dist, n=10**6, bins=100):\n",
|
||||
" \"Sample the distribution n times and make a histogram of the results.\"\n",
|
||||
" samples = [dist() for _ in range(n)]\n",
|
||||
" plt.hist(samples, bins=bins, normed=True)\n",
|
||||
" plt.hist(samples, bins=bins, density=True)\n",
|
||||
" plt.title('{} (μ = {:.1f})'.format(dist.__name__, mean(samples)))\n",
|
||||
" plt.grid(axis='x')\n",
|
||||
" plt.yticks([], '')\n",
|
||||
|
||||
860
ipynb/RaceTrack.ipynb
Normal file
860
ipynb/RaceTrack.ipynb
Normal file
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
719
ipynb/SplitStates.ipynb
Normal file
719
ipynb/SplitStates.ipynb
Normal file
@@ -0,0 +1,719 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<div style=\"text-align:right\"><i>Peter Norvig<br>June 2021</i></div>\n",
|
||||
"\n",
|
||||
"# Split the States\n",
|
||||
"\n",
|
||||
"The [538 Riddler for 11 June 2021](https://fivethirtyeight.com/features/can-you-split-the-states/) poses this problem (paraphrased):\n",
|
||||
"\n",
|
||||
"> Given a map of the lower 48 states of the USA, remove a subset of the states so that the map is cut into two disjoint contiguous regions that are near-halves by area. Call the regions *A* and *B*, where *A* has the larger area. You can treat Michigan’s upper and lower peninsulas as two non-adjacent \"states,\" for a total of 49. \n",
|
||||
">\n",
|
||||
"> To be precise, 538's question is: \n",
|
||||
">\n",
|
||||
"> **1.** What states should you remove to maximize the area of *B*? What is *B*'s area and percent of the country's area?\n",
|
||||
">\n",
|
||||
"> There is some ambiguity in the phrase \"near-halves by area\" and [Philip Bump](https://twitter.com/pbump/status/1400185939629117442) is interested in a second question:\n",
|
||||
">\n",
|
||||
"> **2.** What states should you remove to minimize the difference of the area of *A* and the area of *B*? \n",
|
||||
">\n",
|
||||
"> Philip Bump hypothesized that {IL, MO, OK, NM} is the best subset to remove. Is he right?\n",
|
||||
"\n",
|
||||
"# Vocabulary terms \n",
|
||||
"\n",
|
||||
"Let's start by clarifying some concepts:\n",
|
||||
"- **State**: denoted by the standard 2-letter abbreviations like `'CA'` (plus `'UP'` and `'LP'` for the Michigan peninsulas). \n",
|
||||
"- **States**: a set of states; implemented as a (hashable) `frozenset`. I'll use `states('OR CA')` for `frozenset({'OR', 'CA'})`.\n",
|
||||
"- **Region**: a set of states that are **contiguous**—they are all connected by a single tree of **neighbor** relations.\n",
|
||||
"- **Neighbor**: a relation saying two states share a border. Implemented as [adjacency sets](https://en.wikipedia.org/wiki/Adjacency_list) in the dict `neighbors`.\n",
|
||||
"- **Cut**: a set of states that, when removed from the map, cuts the map into disjoint regions. \n",
|
||||
"- **Split**: a tuple `(A, B, C)`, where `A` and `B` are the two regions made by the cut `C`, with `A` larger than `B`.\n",
|
||||
"- **Border**: the states on the edge of the map (neighbors of Canada, Mexico, Atlantic, or Pacific).\n",
|
||||
"- **Area**: Each state has an area in square miles, given by the `areas` dict, and a region has a total area, given by the function `area`.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Code to implement the concepts: "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import *\n",
|
||||
"from collections import defaultdict\n",
|
||||
"\n",
|
||||
"State = str # Two-letter abbrerviation\n",
|
||||
"States = frozenset # Any set of states\n",
|
||||
"Region = frozenset # A contiguous set of states\n",
|
||||
"Split = Tuple[Region, Region, Region] # (A, B, C) = (large region, small region, cut)\n",
|
||||
"\n",
|
||||
"def states(string) -> States: \"Set of states\"; return States(string.split())\n",
|
||||
"def statedict(**dic) -> dict: \"{State:States}\"; return {ST: states(dic[ST]) for ST in dic}\n",
|
||||
"\n",
|
||||
"neighbors = statedict( # https://theincidentaleconomist.com/wordpress/list-of-neighboring-states-with-stata-code/\n",
|
||||
" AK='', AL='FL GA MS TN', AR='LA MO MS OK TN TX', AZ='CA CO NM NV UT', CA='AZ NV OR', \n",
|
||||
" CO='AZ KS NE NM OK UT WY', CT='MA NY RI', DC='MD VA', DE='MD NJ PA', FL='AL GA', \n",
|
||||
" GA='AL FL NC SC TN', HI='', IA='IL MN MO NE SD WI', ID='MT NV OR UT WA WY', IL='IA IN KY MO WI', \n",
|
||||
" IN='IL KY LP MI OH', KS='CO MO NE OK', KY='IL IN MO OH TN VA WV', LA='AR MS TX', \n",
|
||||
" MA='CT NH NY RI VT', MD='DC DE PA VA WV', ME='NH', MI='IN OH WI', MN='IA ND SD WI', \n",
|
||||
" MO='AR IA IL KS KY NE OK TN', MS='AL AR LA TN', MT='ID ND SD WY', NC='GA SC TN VA', \n",
|
||||
" ND='MN MT SD', NE='CO IA KS MO SD WY', NH='MA ME VT', NJ='DE NY PA', NM='AZ CO OK TX UT', \n",
|
||||
" NV='AZ CA ID OR UT', NY='CT MA NJ PA VT', OH='IN KY LP MI PA WV', OK='AR CO KS MO NM TX', \n",
|
||||
" OR='CA ID NV WA', PA='DE MD NJ NY OH WV', RI='CT MA', SC='GA NC', SD='IA MN MT ND NE WY', \n",
|
||||
" TN='AL AR GA KY MO MS NC VA', TX='AR LA NM OK', UT='AZ CO ID NM NV WY', VA='DC KY MD NC TN WV', \n",
|
||||
" VT='MA NH NY', WA='ID OR', WI='IA IL MI MN UP', WV='KY MD OH PA VA', WY='CO ID MT NE SD UT', \n",
|
||||
" UP='WI', LP='IN OH')\n",
|
||||
"\n",
|
||||
"def area(states) -> int: \"Total area\"; return sum(areas[s] for s in states)\n",
|
||||
"\n",
|
||||
"areas = dict( # https://www.census.gov/geographies/reference-files/2010/geo/state-area.html\n",
|
||||
" AK=665384, AL=52420, AZ=113990, AR=53179, CA=163695, CO=104094, CT=5543, DE=2489, DC=68, \n",
|
||||
" FL=65758, GA=59425, HI=10932, ID=83569, IL=57914, IN=36420, IA=56273, KS=82278, KY=40408, \n",
|
||||
" LA=52378, ME=35380, MD=12406, MA=10554, MI=96714, MN=86936, MS=48432, MO=69707, MT=147040, \n",
|
||||
" NE=77348, NV=110572, NH=9349, NJ=8723, NM=121590, NY=54555, NC=53819, ND=70698, OH=44826, \n",
|
||||
" OK=69899, OR=98379, PA=46054, RI=1545, SC=32020, SD=77116, TN=42144, TX=268596, UT=84897, \n",
|
||||
" VT=9616, VA=42775, WA=71298, WV=24230, WI=65496, WY=97813, UP=16377, LP=80337) \n",
|
||||
"\n",
|
||||
"# Borders:\n",
|
||||
"north = states('WA ID MT ND MN WI MI UP IL IN LP OH PA NY VT NH ME') \n",
|
||||
"south = states('CA AZ NM TX LA MS AL FL') \n",
|
||||
"west = states('WA OR CA')\n",
|
||||
"east = states('ME NH MA RI CT NY NJ DE MD VA NC SC GA FL')\n",
|
||||
"border = north | south | west | east\n",
|
||||
"\n",
|
||||
"# \"Countries\":\n",
|
||||
"usa50 = States(areas) - states('DC UP LP') # 50 actual US states\n",
|
||||
"usa49 = States(areas) - states('AK HI DC MI') # lower 49 \"states\": MI split into UP, LP\n",
|
||||
"usa48 = States(areas) - states('AK HI DC UP LP') # lower 48 states\n",
|
||||
"four = states('UT CO AZ NM') # The \"four corners\" states\n",
|
||||
"western = states('WA OR CA ID NV UT AZ MT WY CO NM') # The 11 states west of the Rockies"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Strategy for answering the two questions\n",
|
||||
"\n",
|
||||
"My overall strategy:\n",
|
||||
"- Generate a large number of **cuts**. \n",
|
||||
"- For each cut *C*, determine the **split** into regions *A* and *B*. Discard cuts that don't produce exactly two regions.\n",
|
||||
"- Find the split that **maximizes** the area of *B*, and the split that **minimizes** the difference in area of *A* and *B*.\n",
|
||||
"\n",
|
||||
"# Making cuts\n",
|
||||
"\n",
|
||||
"Is it feasible to consider all possible cuts? A cut is a subset of the 49 states, so there are 2<sup>49</sup> or 500 trillion possible cuts, so **no**, we can't look at them all. I have four ideas to reduce the number of cuts considered:\n",
|
||||
"- **Limit the total area in a cut.** A large area in the cut means there won't be much area left to make *B* big. \n",
|
||||
"- **Limit the number of states in a cut.** Similarly, if there are too many states in a cut, there won't be many left for *A* or *B*.\n",
|
||||
"- **Make cuts contiguous.** Noncontiguous cuts can't be optimal for question 1, so I won't consider them for now.\n",
|
||||
"- **Make cuts go border-to-border.** A cut can produce exactly two regions only if (a) the cut runs from one place on the border to another place on the border or (b) the cut forms a \"donut\" that surrounds some interior region. The US map isn't big enough to support a decent-sized donut (there are only 14 non-border states, and only KS and NE are not neighbors of a border state). \n",
|
||||
"\n",
|
||||
"By default, the function `make_cuts` will yield all cuts that are contiguous regions up to twice the area and twice the number of states as the {IL, MO, NM, OK} cut, as long as they go from the north border of the US to the south border.\n",
|
||||
"\n",
|
||||
"It starts by building a set of regions where each region contains a single `start` state. Then in each iteration of the `while` loop, it yields each region from the current set of regions that intersects the `end` states, and creates a new set of regions formed by adding a neighboring state to a current region in all possible ways, as long as the area does not exceed `maxarea` and the size does not exceed `maxsize`. (On each iteration all the regions have the same size.)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"maxarea = 2 * area(states('IL MO NM OK'))\n",
|
||||
"\n",
|
||||
"def make_cuts(country, maxsize=8, maxarea=maxarea, start=north, end=south) -> Iterator[Region]:\n",
|
||||
" \"\"\"All contiguous regions up to `maxsize` and `maxarea` that contain a `start` and `end` state.\"\"\"\n",
|
||||
" regions = {Region({s}) for s in start & country} \n",
|
||||
" while regions:\n",
|
||||
" yield from filter(end.intersection, regions) \n",
|
||||
" regions = {region | {s1}\n",
|
||||
" for region in regions if len(region) + 1 <= maxsize \n",
|
||||
" for s in region for s1 in (neighbors[s] & country) - region\n",
|
||||
" if area(region) + areas[s1] <= maxarea} "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"For example, the north-south cuts of size up to 3 states:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{frozenset({'AZ', 'ID', 'UT'}),\n",
|
||||
" frozenset({'ID', 'NM', 'UT'}),\n",
|
||||
" frozenset({'CA', 'ID', 'OR'}),\n",
|
||||
" frozenset({'CA', 'ID', 'NV'}),\n",
|
||||
" frozenset({'AZ', 'ID', 'NV'}),\n",
|
||||
" frozenset({'CA', 'OR', 'WA'})}"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"set(make_cuts(usa49, 3))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Making splits\n",
|
||||
"\n",
|
||||
"Now, given some cuts, the function `make_splits` creates **splits**: tuples `(A, B, C)`, where `A` and `B` are the two regions defined by the cut `C`, with `A` larger than `B`. A split requires that the cut divides the country into exactly two regions, but not all cuts do that. For example, the cut {WA, OR, CA} leaves only one region (consisting of all the other states). The cut {ID, OR, NV, AZ} leaves three regions: {WA}, {CA}, and {everything else}. To verify whether the cut makes two regions, `make_splits` first finds a maximal-size contiguous region `A` from the non-cut states, then finds a region `B` from the remaining states, then checks that `A` and `B` are non-empty and make up all the non-cut states.\n",
|
||||
"\n",
|
||||
"We find the extent of a region with the `floodfill` [algorithm](https://en.wikipedia.org/wiki/Flood_fill): it maintains a mutable `region` and a `frontier` of the states that neighbor the region but are not in the region. We iterate adding the frontier into the region and computing a new frontier until there is no new frontier. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def make_splits(country, cuts) -> Iterator[Split]:\n",
|
||||
" \"\"\"For each cut C, find regions A and B and yield the Split (A, B, C) if valid.\"\"\"\n",
|
||||
" for C in cuts:\n",
|
||||
" noncut = country - C\n",
|
||||
" A = floodfill(noncut) \n",
|
||||
" B = floodfill(noncut - A)\n",
|
||||
" if A and B and (A | B | C == country):\n",
|
||||
" if area(B) > area(A): A, B = B, A # Ensure A larger than B\n",
|
||||
" B, A = sorted([A, B], key=area) \n",
|
||||
" yield (A, B, C)\n",
|
||||
" \n",
|
||||
"def floodfill(legal: States) -> Region:\n",
|
||||
" \"\"\"Starting at one state, fill out to all legal contiguous states.\"\"\"\n",
|
||||
" region = set() \n",
|
||||
" frontier = {min(legal)} if legal else None\n",
|
||||
" while frontier:\n",
|
||||
" region |= frontier\n",
|
||||
" frontier = {s1 for s in frontier for s1 in neighbors[s]\n",
|
||||
" if s1 in legal and s1 not in region}\n",
|
||||
" return Region(region)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"For example, the splits (*A*, *B*, *C*) of the western states from cuts *C* of size up to 3:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{(frozenset({'CO', 'MT', 'NM', 'WY'}),\n",
|
||||
" frozenset({'CA', 'NV', 'OR', 'WA'}),\n",
|
||||
" frozenset({'AZ', 'ID', 'UT'})),\n",
|
||||
" (frozenset({'CO', 'MT', 'NM', 'UT', 'WY'}),\n",
|
||||
" frozenset({'CA', 'OR', 'WA'}),\n",
|
||||
" frozenset({'AZ', 'ID', 'NV'})),\n",
|
||||
" (frozenset({'AZ', 'CO', 'MT', 'NM', 'UT', 'WY'}),\n",
|
||||
" frozenset({'OR', 'WA'}),\n",
|
||||
" frozenset({'CA', 'ID', 'NV'})),\n",
|
||||
" (frozenset({'AZ', 'CO', 'MT', 'NM', 'NV', 'UT', 'WY'}),\n",
|
||||
" frozenset({'WA'}),\n",
|
||||
" frozenset({'CA', 'ID', 'OR'}))}"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"set(make_splits(western, make_cuts(western, 3)))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# The answers\n",
|
||||
"\n",
|
||||
"The function `answers` puts it all together: makes cuts; makes splits from those cuts; finds the splits that answer the two questions; and depending on the value of the parameter `do`, either prints information in a pretty format, or returns the four values, or both. By default, just print."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def answers(country, maxsize=8, maxarea=maxarea, start=north, end=south, do='print') -> Optional[tuple]:\n",
|
||||
" \"\"\"Find the splits that answer the 2 questions.\n",
|
||||
" Print information in pretty format if 'print' is a substring of `do`.\n",
|
||||
" Return the tuple (cuts, splits, answer1, answer2) if 'return' is a substring of `do`.\"\"\"\n",
|
||||
" cuts = list(make_cuts(country, maxsize, maxarea, start, end))\n",
|
||||
" splits = list(make_splits(country, cuts))\n",
|
||||
" answer1 = max(splits, key=lambda s: area(s[1]))\n",
|
||||
" answer2 = min(splits, key=lambda s: area(s[0]) - area(s[1]))\n",
|
||||
" if 'print' in do:\n",
|
||||
" print(f'{len(country)} states ⇒ {len(cuts):,d} cuts',\n",
|
||||
" f'(maxsize ≤ {maxsize}, area ≤ {maxarea:,d}) ⇒ {len(splits):,d} splits.')\n",
|
||||
" show('1. Split that maximizes area(B)', country, answer1)\n",
|
||||
" show('2. Split that minimizes ∆ = area(A) - area(B)', country, answer2)\n",
|
||||
" if 'return' in do:\n",
|
||||
" return cuts, splits, answer1, answer2\n",
|
||||
" \n",
|
||||
"def show(title, country, split):\n",
|
||||
" \"\"\"Print a title, and a summary of the split in four rows. The columns shown are:\n",
|
||||
" 'region name|area|percent of country area|number of states in region|states in region'.\n",
|
||||
" The ∆ row of the table is not a region; it is the difference in area between A and B.\"\"\"\n",
|
||||
" A, B, C = split\n",
|
||||
" def print_row(name, region, sqmi): \n",
|
||||
" statelist = f'{len(region):2d}|{{{\",\".join(sorted(region))}}}' if region else ''\n",
|
||||
" print(f'{name}|{sqmi:9,d}|{sqmi/area(country):5.1%}|{statelist}')\n",
|
||||
" print(f'\\n{title}:')\n",
|
||||
" print_row('A', A, area(A))\n",
|
||||
" print_row('B', B, area(B))\n",
|
||||
" print_row('C', C, area(C))\n",
|
||||
" print_row('∆', '', area(A) - area(B))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"49 states ⇒ 43,901 cuts (maxsize ≤ 8, area ≤ 638,220) ⇒ 14,149 splits.\n",
|
||||
"\n",
|
||||
"1. Split that maximizes area(B):\n",
|
||||
"A|1,345,558|43.1%|29|{AL,AR,CT,DE,FL,GA,IN,KS,KY,LA,LP,MA,MD,ME,MS,NC,NH,NJ,NY,OH,OK,PA,RI,SC,TN,TX,VA,VT,WV}\n",
|
||||
"B|1,344,149|43.1%|15|{AZ,CA,IA,ID,MN,MT,ND,NV,OR,SD,UP,UT,WA,WI,WY}\n",
|
||||
"C| 430,653|13.8%| 5|{CO,IL,MO,NE,NM}\n",
|
||||
"∆| 1,409| 0.0%|\n",
|
||||
"\n",
|
||||
"2. Split that minimizes ∆ = area(A) - area(B):\n",
|
||||
"A|1,267,033|40.6%|14|{AZ,CA,IA,ID,MN,MT,ND,NV,OR,UP,UT,WA,WI,WY}\n",
|
||||
"B|1,266,994|40.6%|27|{AL,AR,CT,DE,FL,GA,KS,KY,LA,LP,MA,MD,ME,MS,NC,NH,NJ,NY,OH,OK,PA,RI,SC,TX,VA,VT,WV}\n",
|
||||
"C| 586,333|18.8%| 8|{CO,IL,IN,MO,NE,NM,SD,TN}\n",
|
||||
"∆| 39| 0.0%|\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"answers(usa49)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Adding DC\n",
|
||||
"\n",
|
||||
"Would anything change if we made DC a state (besides, obviously, the voting rights of the citizens)?"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"50 states ⇒ 45,810 cuts (maxsize ≤ 8, area ≤ 638,220) ⇒ 14,137 splits.\n",
|
||||
"\n",
|
||||
"1. Split that maximizes area(B):\n",
|
||||
"A|1,345,626|43.1%|30|{AL,AR,CT,DC,DE,FL,GA,IN,KS,KY,LA,LP,MA,MD,ME,MS,NC,NH,NJ,NY,OH,OK,PA,RI,SC,TN,TX,VA,VT,WV}\n",
|
||||
"B|1,344,149|43.1%|15|{AZ,CA,IA,ID,MN,MT,ND,NV,OR,SD,UP,UT,WA,WI,WY}\n",
|
||||
"C| 430,653|13.8%| 5|{CO,IL,MO,NE,NM}\n",
|
||||
"∆| 1,477| 0.0%|\n",
|
||||
"\n",
|
||||
"2. Split that minimizes ∆ = area(A) - area(B):\n",
|
||||
"A|1,267,062|40.6%|28|{AL,AR,CT,DC,DE,FL,GA,KS,KY,LA,LP,MA,MD,ME,MS,NC,NH,NJ,NY,OH,OK,PA,RI,SC,TX,VA,VT,WV}\n",
|
||||
"B|1,267,033|40.6%|14|{AZ,CA,IA,ID,MN,MT,ND,NV,OR,UP,UT,WA,WI,WY}\n",
|
||||
"C| 586,333|18.8%| 8|{CO,IL,IN,MO,NE,NM,SD,TN}\n",
|
||||
"∆| 29| 0.0%|\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"answers(usa49 | {'DC'})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The cuts are the same, but for question 2, adding DC's 68 square miles to the eastern region means that it is now only 29 square miles larger than the western region (previously it was 39 square miles smaller)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Reuniting Michigan\n",
|
||||
"\n",
|
||||
"What if Michigan counts as one state, rather than two separate penninsulas? What if we then also add in DC?"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"48 states ⇒ 43,941 cuts (maxsize ≤ 8, area ≤ 638,220) ⇒ 19,811 splits.\n",
|
||||
"\n",
|
||||
"1. Split that maximizes area(B):\n",
|
||||
"A|1,348,646|43.2%|30|{AL,CT,DE,FL,GA,IA,IL,IN,KY,MA,MD,ME,MI,MN,MT,NC,ND,NH,NJ,NY,OH,PA,RI,SC,SD,TN,VA,VT,WI,WV}\n",
|
||||
"B|1,341,666|43.0%|12|{AZ,CA,CO,KS,LA,NM,NV,OK,OR,TX,UT,WA}\n",
|
||||
"C| 430,048|13.8%| 6|{AR,ID,MO,MS,NE,WY}\n",
|
||||
"∆| 6,980| 0.2%|\n",
|
||||
"\n",
|
||||
"2. Split that minimizes ∆ = area(A) - area(B):\n",
|
||||
"A|1,267,816|40.6%|13|{AZ,CA,ID,KS,MN,MT,ND,NE,NV,OR,SD,UT,WA}\n",
|
||||
"B|1,267,672|40.6%|28|{AL,AR,CT,DE,FL,GA,IL,IN,KY,LA,MA,MD,ME,MI,MS,NC,NH,NJ,NY,OH,PA,RI,SC,TN,TX,VA,VT,WV}\n",
|
||||
"C| 584,872|18.7%| 7|{CO,IA,MO,NM,OK,WI,WY}\n",
|
||||
"∆| 144| 0.0%|\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"answers(usa48)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"49 states ⇒ 45,856 cuts (maxsize ≤ 8, area ≤ 638,220) ⇒ 19,860 splits.\n",
|
||||
"\n",
|
||||
"1. Split that maximizes area(B):\n",
|
||||
"A|1,348,714|43.2%|31|{AL,CT,DC,DE,FL,GA,IA,IL,IN,KY,MA,MD,ME,MI,MN,MT,NC,ND,NH,NJ,NY,OH,PA,RI,SC,SD,TN,VA,VT,WI,WV}\n",
|
||||
"B|1,341,666|43.0%|12|{AZ,CA,CO,KS,LA,NM,NV,OK,OR,TX,UT,WA}\n",
|
||||
"C| 430,048|13.8%| 6|{AR,ID,MO,MS,NE,WY}\n",
|
||||
"∆| 7,048| 0.2%|\n",
|
||||
"\n",
|
||||
"2. Split that minimizes ∆ = area(A) - area(B):\n",
|
||||
"A|1,267,816|40.6%|13|{AZ,CA,ID,KS,MN,MT,ND,NE,NV,OR,SD,UT,WA}\n",
|
||||
"B|1,267,740|40.6%|29|{AL,AR,CT,DC,DE,FL,GA,IL,IN,KY,LA,MA,MD,ME,MI,MS,NC,NH,NJ,NY,OH,PA,RI,SC,TN,TX,VA,VT,WV}\n",
|
||||
"C| 584,872|18.7%| 7|{CO,IA,MO,NM,OK,WI,WY}\n",
|
||||
"∆| 76| 0.0%|\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"answers(usa48 | {'DC'})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The results are not as good (I think because splitting MI allows IL and IN to be north border states rather than interior states)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Four-state cuts\n",
|
||||
"\n",
|
||||
"If we are restricted to four-state cuts, the proposed {IL, MO, NM, OK} cut is indeed best:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"49 states ⇒ 61 cuts (maxsize ≤ 4, area ≤ 638,220) ⇒ 45 splits.\n",
|
||||
"\n",
|
||||
"1. Split that maximizes area(B):\n",
|
||||
"A|1,607,869|51.5%|18|{AZ,CA,CO,IA,ID,KS,MN,MT,ND,NE,NV,OR,SD,UP,UT,WA,WI,WY}\n",
|
||||
"B|1,193,381|38.2%|27|{AL,AR,CT,DE,FL,GA,IN,KY,LA,LP,MA,MD,ME,MS,NC,NH,NJ,NY,OH,PA,RI,SC,TN,TX,VA,VT,WV}\n",
|
||||
"C| 319,110|10.2%| 4|{IL,MO,NM,OK}\n",
|
||||
"∆| 414,488|13.3%|\n",
|
||||
"\n",
|
||||
"2. Split that minimizes ∆ = area(A) - area(B):\n",
|
||||
"A|1,607,869|51.5%|18|{AZ,CA,CO,IA,ID,KS,MN,MT,ND,NE,NV,OR,SD,UP,UT,WA,WI,WY}\n",
|
||||
"B|1,193,381|38.2%|27|{AL,AR,CT,DE,FL,GA,IN,KY,LA,LP,MA,MD,ME,MS,NC,NH,NJ,NY,OH,PA,RI,SC,TN,TX,VA,VT,WV}\n",
|
||||
"C| 319,110|10.2%| 4|{IL,MO,NM,OK}\n",
|
||||
"∆| 414,488|13.3%|\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"answers(usa49, 4)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Achieving equality on question 2\n",
|
||||
"\n",
|
||||
"Can we find regions with *exactly* equal areas (to the nearest square mile)? The function `make_equals` generates contiguous regions (up to maxsize 10 by default), keeping track of the areas, and when it finds a second disjoint region with the same area, it yields the two regions with their area. \n",
|
||||
"\n",
|
||||
"With `make_cuts` and `make_splits` we generated a contiguous cut first, then checked that the cut formed two valid regions. Now with `make_equals` we generate two equal-area regions first, then check that they are separated by a not-necessarily-contiguous cut."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def make_equals(country, maxsize=10) -> Iterator[Tuple[int, Region, Region]]:\n",
|
||||
" \"\"\"Yield (area, A, B) for disjoint regions A, B up to `maxsize` with exactly equal area.\"\"\"\n",
|
||||
" table = defaultdict(set) # {area: [regions_with_that_area...]}\n",
|
||||
" for A in make_cuts(country, maxsize, area(country) / 2, country, country):\n",
|
||||
" a = area(A)\n",
|
||||
" for B in table[a]:\n",
|
||||
" if separated(A, B):\n",
|
||||
" yield (a, A, B)\n",
|
||||
" table[a].add(A)\n",
|
||||
" \n",
|
||||
"def separated(A, B) -> bool: \n",
|
||||
" \"\"\"Are regions A and B disjoint with no shared border?\"\"\"\n",
|
||||
" return A.isdisjoint(B) and all(neighbors[a].isdisjoint(B) for a in A)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This is the first computation that will take more than a couple of seconds:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"CPU times: user 47.6 s, sys: 525 ms, total: 48.2 s\n",
|
||||
"Wall time: 48.2 s\n",
|
||||
"\n",
|
||||
"Split with ∆ = 0:\n",
|
||||
"A| 874,595|28.0%|10|{AL,FL,GA,KS,LA,MS,NC,NM,OK,TX}\n",
|
||||
"B| 874,595|28.0%|10|{CA,IA,ID,IL,IN,MT,ND,NV,SD,WA}\n",
|
||||
"C|1,371,170|43.9%|29|{AR,AZ,CO,CT,DE,KY,LP,MA,MD,ME,MN,MO,NE,NH,NJ,NY,OH,OR,PA,RI,SC,TN,UP,UT,VA,VT,WI,WV,WY}\n",
|
||||
"∆| 0| 0.0%|\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%time equals = list(make_equals(usa49, 10))\n",
|
||||
"(a, A, B) = max(equals)\n",
|
||||
"show('Split with ∆ = 0', usa49, (A, B, usa49 - A - B))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"There may be larger regions with equal area. I searched up to `maxsize=12` and didn't find anything.\n",
|
||||
"<img src=\"map6.png\" width=690>"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"A difference in area of ∆ = 0 is obviously an optimal answer to question 2. How about question 1? \n",
|
||||
"\n",
|
||||
"# Proving optimality on question 1\n",
|
||||
"\n",
|
||||
"We arbitrarily limited cuts to 8 states, going from the north to south border. To prove that we have the best cut, we'll have to eliminate those constraints, allowing cuts of any number of states going between any border states. This will increase run time, probably by an order of magnitude. Fortunately, we can tighten the area constraint a bit. We found that the cut {CO, IL, MO, NE, NM} produces a region *B* with area 1,344,149, so that means that any cut that is better for question 1 must create a split where the areas of both *A* and *B* are greater than 1,344,149, Therefore, we can lower the `maxarea` for the cut to:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"432062"
|
||||
]
|
||||
},
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"area(usa49) - 2 * 1344149"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"49 states ⇒ 547,779 cuts (maxsize ≤ 49, area ≤ 432,062) ⇒ 42,685 splits.\n",
|
||||
"\n",
|
||||
"1. Split that maximizes area(B):\n",
|
||||
"A|1,345,558|43.1%|29|{AL,AR,CT,DE,FL,GA,IN,KS,KY,LA,LP,MA,MD,ME,MS,NC,NH,NJ,NY,OH,OK,PA,RI,SC,TN,TX,VA,VT,WV}\n",
|
||||
"B|1,344,149|43.1%|15|{AZ,CA,IA,ID,MN,MT,ND,NV,OR,SD,UP,UT,WA,WI,WY}\n",
|
||||
"C| 430,653|13.8%| 5|{CO,IL,MO,NE,NM}\n",
|
||||
"∆| 1,409| 0.0%|\n",
|
||||
"\n",
|
||||
"2. Split that minimizes ∆ = area(A) - area(B):\n",
|
||||
"A|1,345,558|43.1%|29|{AL,AR,CT,DE,FL,GA,IN,KS,KY,LA,LP,MA,MD,ME,MS,NC,NH,NJ,NY,OH,OK,PA,RI,SC,TN,TX,VA,VT,WV}\n",
|
||||
"B|1,344,149|43.1%|15|{AZ,CA,IA,ID,MN,MT,ND,NV,OR,SD,UP,UT,WA,WI,WY}\n",
|
||||
"C| 430,653|13.8%| 5|{CO,IL,MO,NE,NM}\n",
|
||||
"∆| 1,409| 0.0%|\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"answers(usa49, maxsize=49, maxarea=area(usa49) - 2 * 1344149, start=border, end=border)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This confirms that {CO, IL, MO, NE, NM} is indeed the optimal cut for question 1."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Unit tests\n",
|
||||
"\n",
|
||||
"Here are some unit tests; they also serve as examples of input/output of the various functions:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'ok'"
|
||||
]
|
||||
},
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"def test():\n",
|
||||
" assert states('AZ CA OR') == frozenset({'AZ', 'CA', 'OR'})\n",
|
||||
"\n",
|
||||
" assert len(usa48) == 48 and len(usa49) == 49 and len(usa50) == 50\n",
|
||||
" assert len(western) == 11 and len(four) == 4\n",
|
||||
" \n",
|
||||
" assert set(areas) == set(neighbors)\n",
|
||||
" assert areas['MI'] == areas['UP'] + areas['LP'] \n",
|
||||
" assert area(states('AZ CA OR')) == area(states('IA IL KY NE SD VA WV')) == 376_064\n",
|
||||
"\n",
|
||||
" assert all((x in neighbors[y]) == (y in neighbors[x]) \n",
|
||||
" for x in neighbors for y in neighbors)\n",
|
||||
" \n",
|
||||
" assert set(make_cuts(western, 3)) == {\n",
|
||||
" states('AZ ID NV'),\n",
|
||||
" states('CA ID OR'),\n",
|
||||
" states('CA OR WA'),\n",
|
||||
" states('CA ID NV'),\n",
|
||||
" states('ID NM UT'),\n",
|
||||
" states('AZ ID UT')}\n",
|
||||
"\n",
|
||||
" assert set(make_splits(western, make_cuts(western, 3))) == {\n",
|
||||
" (states('CO MT NM WY'), states('CA NV OR WA'), states('AZ ID UT')),\n",
|
||||
" (states('CO MT NM UT WY'), states('CA OR WA'), states('AZ ID NV')),\n",
|
||||
" (states('AZ CO MT NM UT WY'), states('OR WA'), states('CA ID NV')),\n",
|
||||
" (states('AZ CO MT NM NV UT WY'), states('WA'), states('CA ID OR'))}\n",
|
||||
"\n",
|
||||
" assert set(make_cuts(four, 4, maxarea, four, four)) == {\n",
|
||||
" states('UT'), states('CO'), states('AZ'), states('NM'),\n",
|
||||
" states('AZ CO'), states('AZ NM'), states('CO NM'), states('NM UT'), states('AZ UT'), states('CO UT'),\n",
|
||||
" states('AZ CO UT'), states('AZ CO NM'), states('CO NM UT'), states('AZ NM UT'),\n",
|
||||
" states('AZ CO NM UT')}\n",
|
||||
"\n",
|
||||
" assert floodfill(western - states('AZ ID NV')) == states('CA OR WA')\n",
|
||||
" \n",
|
||||
" for country in (usa48, usa49, border, western, four):\n",
|
||||
" assert floodfill(country) == country\n",
|
||||
" \n",
|
||||
" assert set(make_equals(usa49, 5)) == {\n",
|
||||
" (207853, states('LP MD OH PA WV'), states('IA MO UP WI')),\n",
|
||||
" (258498, states('AL KY MO NC TN'), states('ID SD WY'))}\n",
|
||||
" \n",
|
||||
" assert not separated(south, states('GA SC'))\n",
|
||||
" assert separated(north, south)\n",
|
||||
" \n",
|
||||
" return 'ok'\n",
|
||||
" \n",
|
||||
"test()"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.7.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
BIN
ipynb/SquareSum15.jpg
Normal file
BIN
ipynb/SquareSum15.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 47 KiB |
456
ipynb/StarBattle.ipynb
Normal file
456
ipynb/StarBattle.ipynb
Normal file
@@ -0,0 +1,456 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<div align=\"right\" style=\"text-align: right\"><i>Peter Norvig<br>Aug 2021</i></div>\n",
|
||||
"\n",
|
||||
"# Star Battle Puzzles\n",
|
||||
"\n",
|
||||
"If you thought this notebook was going to be about a video game like StarCraft®, I'm sorry to disapoint you. Instead it is about [**Star Battle puzzles**](https://www.puzzle-star-battle.com/), a genre of Sudoku-like puzzles with these properties:\n",
|
||||
"\n",
|
||||
"- Like Sudoku, you start with an *N*×*N* board and fill in cells.\n",
|
||||
"- Like Sudoku, an *N*×*N* board has 3*N* **units**: *N* columns, *N* rows, and *N* boxes.\n",
|
||||
"- Like Sudoku, a well-formed puzzle has exactly one solution.\n",
|
||||
"- Unlike Sudoku, the boxes have irregular shapes (not squares) and differing numbers of cells.\n",
|
||||
"- Unlike Sudoku, there are only 2 possible values for each cell: star or blank (not 9 digits).\n",
|
||||
"- Unlike Sudoku,\n",
|
||||
"- The constraints are:\n",
|
||||
" - Each unit (column, row, or box) must have exactly *S* stars.\n",
|
||||
" - Two stars cannot be adjacent (not even diagonally).\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Here is a board (*S*=2, *N*=10) and its solution from a helpful [Star Battle Rules and Info](https://www.gmpuzzles.com/blog/star-battle-rules-and-info/) page:\n",
|
||||
"\n",
|
||||
"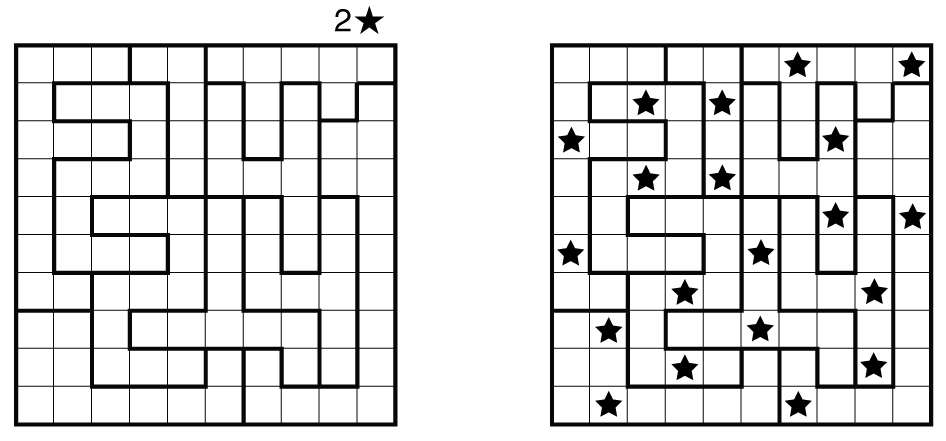\n",
|
||||
"\n",
|
||||
"This “24”-themed puzzle was created by Thomas Snyder for the 24-Hours Puzzle Championship in Hungary in 2012.\n",
|
||||
"\n",
|
||||
"# Representation\n",
|
||||
"\n",
|
||||
"Here's how I will represent Star Battle puzzles:\n",
|
||||
"\n",
|
||||
"- A **cell** is an integer in `range(N * N)`.\n",
|
||||
" - The top row is cells 0, 1, 2, ... left-to-right; the second row is *N*, *N* + 1, *N* + 2, ...; etc.\n",
|
||||
"- A **unit** is a set of cells.\n",
|
||||
"- A **board** is a named tuple with the attributes:\n",
|
||||
" - `N`: the number of cells on each side of the *N*×*N* board.\n",
|
||||
" - `S`: the number of stars per unit in a solution.\n",
|
||||
" - `units`: a list of all the units on the board.\n",
|
||||
" - `units_for`: a dict where `units_for[c]` is a list of the units that cell `c` is in.\n",
|
||||
" - `pic`: a string; a graphical picture of the differently-shaped boxes.\n",
|
||||
"- An intermediate **state** in a search for a solution is a named tuple with the attributes:\n",
|
||||
" - `units`: list of units that have not yet been filled with *S* stars each.\n",
|
||||
" - `stars`: set of cells that have been determined (or guessed) to contain a star.\n",
|
||||
" - `unknowns`: set of cells that might contain either a star or a blank.\n",
|
||||
"- A **solution** is a set of cells where the stars go.\n",
|
||||
"- A **failure** to find a solution is indicated by `None`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from collections import namedtuple\n",
|
||||
"from functools import lru_cache\n",
|
||||
"from typing import Optional, Iterator, Set, List\n",
|
||||
"\n",
|
||||
"Cell = int\n",
|
||||
"Board = namedtuple('Board', 'N, S, units, units_for, pic')\n",
|
||||
"State = namedtuple('State', 'units, stars, unknowns')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Representing Boards\n",
|
||||
"\n",
|
||||
"We can describe the differently-shaped boxes with a **picture** consisting of of *N* lines of *N* non-whitespace characters, where each of *N* distinct characters in the picture corresponds to a box, as in this picture of a 5×5 board with 5 boxes:\n",
|
||||
" \n",
|
||||
" , + ' ' '\n",
|
||||
" , + : : '\n",
|
||||
" , + : : .\n",
|
||||
" , . . . .\n",
|
||||
" , . . . ."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def make_board(S, picture) -> Board:\n",
|
||||
" \"\"\"Create a `Board` from a picture of the boxes.\"\"\"\n",
|
||||
" pic = ''.join(picture.split()) # eliminate whitespace from picture\n",
|
||||
" N = int(len(pic) ** 0.5) # N is √(number of cells)\n",
|
||||
" assert len(pic) == N * N\n",
|
||||
" side = range(0, N)\n",
|
||||
" cols = [{N * r + c for r in side} for c in side]\n",
|
||||
" rows = [{N * r + c for c in side} for r in side]\n",
|
||||
" boxes = [indexes(pic, ch) for ch in set(pic)] \n",
|
||||
" units = cols + rows + boxes\n",
|
||||
" units_for = {c: [u for u in units if c in u]\n",
|
||||
" for c in range(N * N)}\n",
|
||||
" return Board(N, S, units, units_for, pic)\n",
|
||||
"\n",
|
||||
"def indexes(sequence, item) -> Set[int]:\n",
|
||||
" \"\"\"All indexes in sequence where item appears.\"\"\"\n",
|
||||
" return {i for i in range(len(sequence)) if sequence[i] == item}"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Here's the 5×5 board, and the [board](https://krazydad.com/play/starbattle/?kind=10x10&volumeNumber=1&bookNumber=24&puzzleNumber=18) Barry Hayes shared to introduce me to this type of puzzle, and the \"24\" board. Note that in the \"24\" board the boxes \"2\" and \"t\" form interlocking figure 2s and the boxes \"4\" and \"f\" form interlocking figure 4s."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"board5x5 = make_board(1, \"\"\"\n",
|
||||
", + ' ' '\n",
|
||||
", + : : '\n",
|
||||
", + : : .\n",
|
||||
", . . . .\n",
|
||||
", . . . .\n",
|
||||
"\"\"\")\n",
|
||||
"\n",
|
||||
"board1 = make_board(2, \"\"\"\n",
|
||||
"` . . . . . | ; ; ;\n",
|
||||
"` . . . . . | ; ; ;\n",
|
||||
"` ` ` . . . | ; ; ;\n",
|
||||
"` , ` . . . . ; ; ;\n",
|
||||
", , , . . + + = = =\n",
|
||||
", , : : + + + + + +\n",
|
||||
", : : ' ' ' ' ' ' +\n",
|
||||
", : : - - ' ' ' ' '\n",
|
||||
", : : : - - - ' ' '\n",
|
||||
", , , - - - - ' ' '\n",
|
||||
"\"\"\") \n",
|
||||
"\n",
|
||||
"board24 = make_board(2, \"\"\"\n",
|
||||
". . . ' ' , , , , ,\n",
|
||||
". 2 2 2 ' 4 , 4 , -\n",
|
||||
". . . 2 ' 4 , 4 - -\n",
|
||||
". 2 2 2 ' 4 4 4 - -\n",
|
||||
". 2 t t t ; f 4 f -\n",
|
||||
". 2 2 2 t ; f 4 f -\n",
|
||||
". . t t t ; f f f -\n",
|
||||
": : t ; ; ; ; ; f -\n",
|
||||
": : t t t : - ; f -\n",
|
||||
": : : : : : - - - -\n",
|
||||
"\"\"\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Solving Strategy\n",
|
||||
"\n",
|
||||
"I will solve puzzles using **depth-first search** with **constraint propagation**. \n",
|
||||
"\n",
|
||||
"By \"depth-first search\" I mean a procedure that starts from a current state, then creates a new state with a guess that a star should go into some cell *c*, and then tries to solve the rest of the puzzle from the new state. If there is no solution, back up to the old state and guess a different cell for the star. \n",
|
||||
"\n",
|
||||
"By \"constraint propagation\" I mean that whenever a star is placed, check what implications this has for the rest of the board: what blanks and/or stars *must* be placed in what cells. Constraint propagation may be able to prove that the original guess leads to failure, and it may make future guesses easier. \n",
|
||||
"\n",
|
||||
"Note that search always creates a new state for each guess (leaving the old state unaltered so that we can back up to it) and constraint propagation always mutates the state (because the changes are inevitable consequences, not guesses). \n",
|
||||
"\n",
|
||||
"# Constraint Propagation\n",
|
||||
"\n",
|
||||
"The constraint propagation rules are:\n",
|
||||
" \n",
|
||||
"When we **put a star** in a cell:\n",
|
||||
" - Mutate the current state by adding the cell to the set of stars and removing it from the unknowns.\n",
|
||||
" - If any of the cell's units has more than *S* stars, then fail (return `None`).\n",
|
||||
" - Put a blank in each adjacent cell. If you can't, fail.\n",
|
||||
"\n",
|
||||
"When we **put a blank** in a cell:\n",
|
||||
" - Mutate the current state by removing the cell from the unknowns.\n",
|
||||
" - For each of the cell's units:\n",
|
||||
" - If the number of stars plus unknown cells in the unit is less than *S*, then fail.\n",
|
||||
" - If the number equals *S*, then put stars in the unknown cells. If you can't, fail."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def put_star(cell, board, state) -> Optional[State]:\n",
|
||||
" \"\"\"Put a star on the board in the given cell. Mutates state.\n",
|
||||
" Return `None` if it is not possible to place star.\"\"\"\n",
|
||||
" if cell in state.stars:\n",
|
||||
" return state # Already put star in cell\n",
|
||||
" state.unknowns.remove(cell)\n",
|
||||
" state.stars.add(cell)\n",
|
||||
" for unit in board.units_for[cell]:\n",
|
||||
" if count_stars(unit, state) > board.S:\n",
|
||||
" return None\n",
|
||||
" for c in neighbors(cell, board.N):\n",
|
||||
" if c in state.stars or not put_blank(c, board, state):\n",
|
||||
" return None\n",
|
||||
" return state\n",
|
||||
" \n",
|
||||
"def put_blank(cell, board, state) -> Optional[State]:\n",
|
||||
" \"\"\"Put a blank on the board in the given cell. Mutates state.\n",
|
||||
" Return `None` if it is not possible to place blank.\"\"\"\n",
|
||||
" if cell not in state.unknowns:\n",
|
||||
" return state # Already put blank in cell\n",
|
||||
" state.unknowns.remove(cell)\n",
|
||||
" for unit in board.units_for[cell]:\n",
|
||||
" s = count_stars(unit, state)\n",
|
||||
" unknowns = unit & state.unknowns\n",
|
||||
" if s + len(unknowns) < board.S:\n",
|
||||
" return None\n",
|
||||
" if s + len(unknowns) == board.S:\n",
|
||||
" if not all(put_star(c, board, state) for c in unknowns):\n",
|
||||
" return None\n",
|
||||
" return state"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def count_stars(unit, state) -> int: return len(unit & state.stars)\n",
|
||||
"\n",
|
||||
"@lru_cache()\n",
|
||||
"def neighbors(cell, N) -> Set[Cell]:\n",
|
||||
" \"\"\"The set of cells that neighbor a given cell on an N×N board.\"\"\"\n",
|
||||
" dxs = {0, +1 if cell % N != N - 1 else 0, -1 if cell % N != 0 else 0}\n",
|
||||
" dys = {0, +N if cell + N < N ** 2 else 0, -N if cell >= N else 0}\n",
|
||||
" return {cell + dx + dy \n",
|
||||
" for dy in dys for dx in dxs if dx or dy}"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Depth-First Search\n",
|
||||
"\n",
|
||||
"Here are the two more main functions to do search:\n",
|
||||
"1. `solve(board)`: a wrapper function that calls `search` and prints the results.\n",
|
||||
"2. `search(board, state)`: where the real work of searching for a solution is done."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def solve(board) -> Set[Cell]:\n",
|
||||
" \"\"\"Call `search` with an initial state; print board and return solution stars.\n",
|
||||
" Raise an error if there is no solution.\"\"\"\n",
|
||||
" stars = next(search(board, initial_state(board))).stars\n",
|
||||
" print_board(board, stars)\n",
|
||||
" return stars\n",
|
||||
"\n",
|
||||
"def search(board, state) -> Iterator[State]:\n",
|
||||
" \"\"\"Recursive depth-first search for solution(s) to a Star Battle puzzle.\"\"\"\n",
|
||||
" while state.units and count_stars(state.units[0], state) == board.S:\n",
|
||||
" state.units.pop(0) # Discard filled unit(s)\n",
|
||||
" if not state.units: # Succeed\n",
|
||||
" yield state\n",
|
||||
" else: # Guess and recurse\n",
|
||||
" for c in state.units[0] & state.unknowns:\n",
|
||||
" guess_state = put_star(c, board, copy_state(state))\n",
|
||||
" if guess_state is not None:\n",
|
||||
" yield from search(board, guess_state)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The inputs to `search` are the static `board` and the dynamic `state` of computation, but what the output should be is less obvious; I considered two choices:\n",
|
||||
"1. `search` returns the first state that represents a solution, or `None` if there is no solution.\n",
|
||||
"2. `search` is a generator that yields all states that represent a solution.\n",
|
||||
"\n",
|
||||
"I decided on the second choice for `search`, even though `solve` only looks at the first solution. That way `search` could be used to verify that puzzles are well-formed, for example.`search` works as follows:\n",
|
||||
" - While the state's first unit is already filled with *S* stars, discard that unit and move on to the next one.\n",
|
||||
" - If the state has no remaining unfilled units, then succeed: yield the state.\n",
|
||||
" - Otherwise, guess and recurse: for each unknown cell *c* in the first unit, create a new state with a star in cell *c*, and if placing the star does not lead to constraint-propagation failure then recursively search from that state.\n",
|
||||
"\n",
|
||||
"Below are the remaining minor functions. *Note:* in `initial_state`, the `units` are `sorted` smallest-unit first, because if, say, a board has *S*=2 and the smallest unit has 3 cells, then you have a 2/3 chance of guessing correctly where the 2 stars should go. With larger units you would be more likely to guess wrong and waste time backing up, so better to do small units first and large units later, when constraint propagation has eliminated some unknown cells."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def copy_state(s: State): return State(s.units[:], set(s.stars), set(s.unknowns))\n",
|
||||
"\n",
|
||||
"def initial_state(board) -> State: \n",
|
||||
" \"\"\"The initial state to start the search for a solution to `board`.\"\"\"\n",
|
||||
" return State(units=sorted(board.units, key=len), \n",
|
||||
" stars=set(), unknowns=set(range(board.N ** 2)))\n",
|
||||
"\n",
|
||||
"def print_board(board, stars) -> None:\n",
|
||||
" \"\"\"Print a representation of the board before and after placing the stars.\n",
|
||||
" The output is not beautiful, but it is readable.\"\"\"\n",
|
||||
" N = board.N\n",
|
||||
" def row(chars, i) -> str: return ' '.join(chars[i * N:(i + 1) * N])\n",
|
||||
" filled = [('*' if c in stars else ch) for c, ch in enumerate(board.pic)]\n",
|
||||
" for i in range(N):\n",
|
||||
" print(row(board.pic, i), ' ' * N, row(filled, i))\n",
|
||||
" print('Valid' if is_solution(board, stars) else 'Invalid', 'solution')\n",
|
||||
" \n",
|
||||
"def is_solution(board, stars) -> bool:\n",
|
||||
" \"\"\"Verify that all units have S stars and that stars are non-adjacent.\"\"\"\n",
|
||||
" return (all(len(stars & unit) == board.S\n",
|
||||
" for unit in board.units) and\n",
|
||||
" all(c1 not in neighbors(c2, board.N)\n",
|
||||
" for c1 in stars for c2 in stars))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Solutions\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"solve(board5x5)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"` . . . . . | ; ; ; ` . . . . . * ; * ;\n",
|
||||
"` . . . . . | ; ; ; ` * . . * . | ; ; ;\n",
|
||||
"` ` ` . . . | ; ; ; ` ` ` . . . * ; * ;\n",
|
||||
"` , ` . . . . ; ; ; * , * . . . . ; ; ;\n",
|
||||
", , , . . + + = = = , , , . . + + * = *\n",
|
||||
", , : : + + + + + + , , : * + * + + + +\n",
|
||||
", : : ' ' ' ' ' ' + , * : ' ' ' ' ' ' *\n",
|
||||
", : : - - ' ' ' ' ' , : : * - * ' ' ' '\n",
|
||||
", : : : - - - ' ' ' * : : : - - - * ' '\n",
|
||||
", , , - - - - ' ' ' , , * - * - - ' ' '\n",
|
||||
"Valid solution\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{6, 8, 11, 14, 26, 28, 30, 32, 47, 49, 53, 55, 61, 69, 73, 75, 80, 87, 92, 94}"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"solve(board1)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
". . . ' ' , , , , , . . . ' ' , * , , *\n",
|
||||
". 2 2 2 ' 4 , 4 , - . 2 * 2 * 4 , 4 , -\n",
|
||||
". . . 2 ' 4 , 4 - - * . . 2 ' 4 , * - -\n",
|
||||
". 2 2 2 ' 4 4 4 - - . 2 * 2 * 4 4 4 - -\n",
|
||||
". 2 t t t ; f 4 f - . 2 t t t ; f * f *\n",
|
||||
". 2 2 2 t ; f 4 f - * 2 2 2 t * f 4 f -\n",
|
||||
". . t t t ; f f f - . . t * t ; f f * -\n",
|
||||
": : t ; ; ; ; ; f - : * t ; ; * ; ; f -\n",
|
||||
": : t t t : - ; f - : : t * t : - ; * -\n",
|
||||
": : : : : : - - - - : * : : : : * - - -\n",
|
||||
"Valid solution\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{6, 9, 12, 14, 20, 27, 32, 34, 47, 49, 50, 55, 63, 68, 71, 75, 83, 88, 91, 96}"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"solve(board24)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"CPU times: user 195 ms, sys: 2.98 ms, total: 198 ms\n",
|
||||
"Wall time: 197 ms\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%%time\n",
|
||||
"for board in (board5x5, board1, board24):\n",
|
||||
" assert next(search(board, initial_state(board))).stars"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.7.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
BIN
ipynb/Sudoku$1.class
Normal file
BIN
ipynb/Sudoku$1.class
Normal file
Binary file not shown.
BIN
ipynb/Sudoku$2.class
Normal file
BIN
ipynb/Sudoku$2.class
Normal file
Binary file not shown.
BIN
ipynb/Sudoku.class
Normal file
BIN
ipynb/Sudoku.class
Normal file
Binary file not shown.
1017
ipynb/Sudoku.ipynb
Normal file
1017
ipynb/Sudoku.ipynb
Normal file
File diff suppressed because it is too large
Load Diff
488
ipynb/Sudoku.java
Normal file
488
ipynb/Sudoku.java
Normal file
@@ -0,0 +1,488 @@
|
||||
import java.io.*;
|
||||
import java.lang.Integer.*;
|
||||
import java.util.*;
|
||||
import java.util.stream.*;
|
||||
import java.lang.StringBuilder;
|
||||
import java.util.concurrent.CountDownLatch;
|
||||
|
||||
//////////////////////////////// Solve Sudoku Puzzles ////////////////////////////////
|
||||
//////////////////////////////// @author Peter Norvig ////////////////////////////////
|
||||
|
||||
/** There are two representations of puzzles that we will use:
|
||||
** 1. A gridstring is 81 chars, with characters '0' or '.' for blank and '1' to '9' for digits.
|
||||
** 2. A puzzle grid is an int[81] with a digit d (1-9) represented by the integer (1 << (d - 1));
|
||||
** that is, a bit pattern that has a single 1 bit representing the digit.
|
||||
** A blank is represented by the OR of all the digits 1-9, meaning that any digit is possible.
|
||||
** While solving the puzzle, some of these digits are eliminated, leaving fewer possibilities.
|
||||
** The puzzle is solved when every square has only a single possibility.
|
||||
**
|
||||
** Search for a solution with `search`:
|
||||
** - Fill an empty square with a guessed digit and do constraint propagation.
|
||||
** - If the guess is consistent, search deeper; if not, try a different guess for the square.
|
||||
** - If all guesses fail, back up to the previous level.
|
||||
** - In selecting an empty square, we pick one that has the minimum number of possible digits.
|
||||
** - To be able to back up, we need to keep the grid from the previous recursive level.
|
||||
** But we only need to keep one grid for each level, so to save garbage collection,
|
||||
** we pre-allocate one grid per level (there are 81 levels) in a `gridpool`.
|
||||
** Do constraint propagation with `arcConsistent`, `dualConsistent`, and `nakedPairs`.
|
||||
**/
|
||||
|
||||
public class Sudoku {
|
||||
|
||||
//////////////////////////////// main; command line options //////////////////////////////
|
||||
|
||||
static final String usage = String.join("\n",
|
||||
"usage: java Sudoku -(no)[fghnprstuv] | -[RT]<number> | <filename> ...",
|
||||
"E.g., -v turns verify flag on, -nov turns it off. -R and -T require a number. The options:\n",
|
||||
" -f(ile) Print summary stats for each file (default on)",
|
||||
" -g(rid) Print each puzzle grid and solution grid (default off)",
|
||||
" -h(elp) Print this usage message",
|
||||
" -n(aked) Run naked pairs (default on)",
|
||||
" -p(uzzle) Print summary stats for each puzzle (default off)",
|
||||
" -r(everse) Solve the reverse of each puzzle as well as each puzzle itself (default off)",
|
||||
" -s(earch) Run search (default on, but some puzzles can be solved with CSP methods alone)",
|
||||
" -t(hread) Print summary stats for each thread (default off)",
|
||||
" -u(nitTest)Run a suite of unit tests (default off)",
|
||||
" -v(erify) Verify each solution is valid (default on)",
|
||||
" -T<number> Concurrently run <number> threads (default 26)",
|
||||
" -R<number> Repeat each puzzle <number> times (default 1)",
|
||||
" <filename> Solve all puzzles in filename, which has one puzzle per line");
|
||||
|
||||
boolean printFileStats = true; // -f
|
||||
boolean printGrid = false; // -g
|
||||
boolean runNakedPairs = true; // -n
|
||||
boolean printPuzzleStats = false; // -p
|
||||
boolean reversePuzzle = false; // -r
|
||||
boolean runSearch = true; // -s
|
||||
boolean printThreadStats = false; // -t
|
||||
boolean verifySolution = true; // -v
|
||||
int nThreads = 26; // -T
|
||||
int repeat = 1; // -R
|
||||
|
||||
int backtracks = 0; // count total backtracks
|
||||
|
||||
/** Parse command line args and solve puzzles in files. **/
|
||||
public static void main(String[] args) throws IOException {
|
||||
Sudoku s = new Sudoku();
|
||||
for (String arg: args) {
|
||||
if (!arg.startsWith("-")) {
|
||||
s.solveFile(arg);
|
||||
} else {
|
||||
boolean value = !arg.startsWith("-no");
|
||||
switch(arg.charAt(value ? 1 : 3)) {
|
||||
case 'f': s.printFileStats = value; break;
|
||||
case 'g': s.printGrid = value; break;
|
||||
case 'h': System.out.println(usage); break;
|
||||
case 'n': s.runNakedPairs = value; break;
|
||||
case 'p': s.printPuzzleStats = value; break;
|
||||
case 'r': s.reversePuzzle = value; break;
|
||||
case 's': s.runSearch = value; break;
|
||||
case 't': s.printThreadStats = value; break;
|
||||
case 'u': s.runUnitTests(); break;
|
||||
case 'v': s.verifySolution = value; break;
|
||||
case 'T': s.nThreads = Integer.parseInt(arg.substring(2)); break;
|
||||
case 'R': s.repeat = Integer.parseInt(arg.substring(2)); break;
|
||||
default: System.out.println("Unrecognized option: " + arg + "\n" + usage);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
//////////////////////////////// Handling Lists of Puzzles ////////////////////////////////
|
||||
|
||||
/** Solve all the puzzles in a file. Report timing statistics. **/
|
||||
void solveFile(String filename) throws IOException {
|
||||
List<int[]> grids = readFile(filename);
|
||||
long startFileTime = System.nanoTime();
|
||||
switch(nThreads) {
|
||||
case 1: solveList(grids); break;
|
||||
default: solveListThreaded(grids, nThreads); break;
|
||||
}
|
||||
if (printFileStats) printStats(grids.size() * repeat, startFileTime, filename);
|
||||
}
|
||||
|
||||
|
||||
/** Solve a list of puzzles in a single thread.
|
||||
** repeat -R<number> times; print each puzzle's stats if -p; print grid if -g; verify if -v. **/
|
||||
void solveList(List<int[]> grids) {
|
||||
int[] puzzle = new int[N * N]; // Used to save a copy of the original grid
|
||||
int[][] gridpool = new int[N * N][N * N]; // Reuse grids during the search
|
||||
for (int g=0; g<grids.size(); ++g) {
|
||||
int grid[] = grids.get(g);
|
||||
System.arraycopy(grid, 0, puzzle, 0, grid.length);
|
||||
for (int i = 0; i < repeat; ++i) {
|
||||
long startTime = printPuzzleStats ? System.nanoTime() : 0;
|
||||
int[] solution = initialize(grid); // All the real work is
|
||||
if (runSearch) solution = search(solution, gridpool, 0); // on these 2 lines.
|
||||
if (printPuzzleStats) {
|
||||
printStats(1, startTime, "Puzzle " + (g + 1));
|
||||
}
|
||||
if (i == 0 && (printGrid || (verifySolution && !verify(solution, puzzle)))) {
|
||||
printGrids("Puzzle " + (g + 1), grid, solution);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
/** Break a list of puzzles into nThreads sublists and solve each sublist in a separate thread. **/
|
||||
void solveListThreaded(List<int[]> grids, int nThreads) {
|
||||
try {
|
||||
final long startTime = System.nanoTime();
|
||||
int nGrids = grids.size();
|
||||
final CountDownLatch latch = new CountDownLatch(nThreads);
|
||||
int size = nGrids / nThreads;
|
||||
for (int c = 0; c < nThreads; ++c) {
|
||||
int end = c == nThreads - 1 ? nGrids : (c + 1) * size;
|
||||
final List<int[]> sublist = grids.subList(c * size, end);
|
||||
new Thread() {
|
||||
public void run() {
|
||||
solveList(sublist);
|
||||
latch.countDown();
|
||||
if (printThreadStats) {
|
||||
printStats(repeat * sublist.size(), startTime, "Thread");
|
||||
}
|
||||
}
|
||||
}.start();
|
||||
}
|
||||
latch.await(); // Wait for all threads to finish
|
||||
} catch (InterruptedException e) {
|
||||
System.err.println("And you may ask yourself, 'Well, how did I get here?'");
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
//////////////////////////////// Utility functions ////////////////////////////////
|
||||
|
||||
/** Return an array of all squares in the intersection of these rows and cols **/
|
||||
int[] cross(int[] rows, int[] cols) {
|
||||
int[] result = new int[rows.length * cols.length];
|
||||
int i = 0;
|
||||
for (int r: rows) { for (int c: cols) { result[i++] = N * r + c; } }
|
||||
return result;
|
||||
}
|
||||
|
||||
|
||||
/** Return true iff item is an element of array, or of array[0:end]. **/
|
||||
boolean member(int item, int[] array) { return member(item, array, array.length); }
|
||||
boolean member(int item, int[] array, int end) {
|
||||
for (int i = 0; i<end; ++i) {
|
||||
if (array[i] == item) { return true; }
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
|
||||
//////////////////////////////// Constants ////////////////////////////////
|
||||
|
||||
final int N = 9; // Number of cells on a side of grid.
|
||||
final int[] DIGITS = {1<<0, 1<<1, 1<<2, 1<<3, 1<<4, 1<<5, 1<<6, 1<<7, 1<<8};
|
||||
final int ALL_DIGITS = Integer.parseInt("111111111", 2);
|
||||
final int[] ROWS = IntStream.range(0, N).toArray();
|
||||
final int[] COLS = ROWS;
|
||||
final int[] SQUARES = IntStream.range(0, N * N).toArray();
|
||||
final int[][] BLOCKS = {{0, 1, 2}, {3, 4, 5}, {6, 7, 8}};
|
||||
final int[][] ALL_UNITS = new int[3 * N][];
|
||||
final int[][][] UNITS = new int[N * N][3][N];
|
||||
final int[][] PEERS = new int[N * N][20];
|
||||
final int[] NUM_DIGITS = new int[ALL_DIGITS + 1];
|
||||
final int[] HIGHEST_DIGIT = new int[ALL_DIGITS + 1];
|
||||
|
||||
{
|
||||
// Initialize ALL_UNITS to be an array of the 27 units: rows, columns, and blocks
|
||||
int i = 0;
|
||||
for (int r: ROWS) {ALL_UNITS[i++] = cross(new int[] {r}, COLS); }
|
||||
for (int c: COLS) {ALL_UNITS[i++] = cross(ROWS, new int[] {c}); }
|
||||
for (int[] rb: BLOCKS) {for (int[] cb: BLOCKS) {ALL_UNITS[i++] = cross(rb, cb); } }
|
||||
|
||||
// Initialize each UNITS[s] to be an array of the 3 units for square s.
|
||||
for (int s: SQUARES) {
|
||||
i = 0;
|
||||
for (int[] u: ALL_UNITS) {
|
||||
if (member(s, u)) UNITS[s][i++] = u;
|
||||
}
|
||||
}
|
||||
|
||||
// Initialize each PEERS[s] to be an array of the 20 squares that are peers of square s.
|
||||
for (int s: SQUARES) {
|
||||
i = 0;
|
||||
for (int[] u: UNITS[s]) {
|
||||
for (int s2: u) {
|
||||
if (s2 != s && !member(s2, PEERS[s], i)) {
|
||||
PEERS[s][i++] = s2;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Initialize NUM_DIGITS[val] to be the number of 1 bits in the bitset val
|
||||
// and HIGHEST_DIGIT[val] to the highest bit set in the bitset val
|
||||
for (int val = 0; val <= ALL_DIGITS; val++) {
|
||||
NUM_DIGITS[val] = Integer.bitCount(val);
|
||||
HIGHEST_DIGIT[val] = Integer.highestOneBit(val);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
//////////////////////////////// Search algorithm ////////////////////////////////
|
||||
|
||||
/** Search for a solution to grid. If there is an unfilled square, select one
|
||||
** and try--that is, search recursively--every possible digit for the square. **/
|
||||
int[] search(int[] grid, int[][] gridpool, int level) {
|
||||
if (grid == null) {
|
||||
return null;
|
||||
}
|
||||
int s = select_square(grid);
|
||||
if (s == -1) {
|
||||
return grid; // No squares to select means we are done!
|
||||
}
|
||||
for (int d: DIGITS) {
|
||||
// For each possible digit d that could fill square s, try it
|
||||
if ((d & grid[s]) > 0) {
|
||||
// Copy grid's contents into gridpool[level], and use that at the next level
|
||||
System.arraycopy(grid, 0, gridpool[level], 0, grid.length);
|
||||
int[] result = search(fill(gridpool[level], s, d), gridpool, level + 1);
|
||||
if (result != null) {
|
||||
return result;
|
||||
}
|
||||
backtracks += 1;
|
||||
}
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
|
||||
/** Verify that grid is a solution to the puzzle. **/
|
||||
boolean verify(int[] grid, int[] puzzle) {
|
||||
if (grid == null) { return false; }
|
||||
// Check that all squares have a single digit, and
|
||||
// no filled square in the puzzle was changed in the solution.
|
||||
for (int s: SQUARES) {
|
||||
if ((NUM_DIGITS[grid[s]] != 1) || (NUM_DIGITS[puzzle[s]] == 1 && grid[s] != puzzle[s])) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
// Check that each unit is a permutation of digits
|
||||
for (int[] u: ALL_UNITS) {
|
||||
int unit_digits = 0; // All the digits in a unit.
|
||||
for (int s : u) {unit_digits |= grid[s]; }
|
||||
if (unit_digits != ALL_DIGITS) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
/** Choose an unfilled square with the minimum number of possible values.
|
||||
** If all squares are filled, return -1 (which means the puzzle is complete). **/
|
||||
int select_square(int[] grid) {
|
||||
int square = -1;
|
||||
int min = N + 1;
|
||||
for (int s: SQUARES) {
|
||||
int c = NUM_DIGITS[grid[s]];
|
||||
if (c == 2) {
|
||||
return s; // Can't get fewer than 2 possible digits
|
||||
} else if (c > 1 && c < min) {
|
||||
square = s;
|
||||
min = c;
|
||||
}
|
||||
}
|
||||
return square;
|
||||
}
|
||||
|
||||
|
||||
/** fill grid[s] = d. If this leads to contradiction, return null. **/
|
||||
int[] fill(int[] grid, int s, int d) {
|
||||
if ((grid == null) || ((grid[s] & d) == 0)) { return null; } // d not possible for grid[s]
|
||||
grid[s] = d;
|
||||
for (int p: PEERS[s]) {
|
||||
if (!eliminate(grid, p, d)) { // If we can't eliminate d from all peers of s, then fail
|
||||
return null;
|
||||
}
|
||||
}
|
||||
return grid;
|
||||
}
|
||||
|
||||
|
||||
/** Eliminate digit d as a possibility for grid[s].
|
||||
** Run the 3 constraint propagation routines.
|
||||
** If constraint propagation detects a contradiction, return false. **/
|
||||
boolean eliminate(int[] grid, int s, int d) {
|
||||
if ((grid[s] & d) == 0) { return true; } // d already eliminated from grid[s]
|
||||
grid[s] -= d;
|
||||
return arc_consistent(grid, s) && dual_consistent(grid, s, d) && naked_pairs(grid, s);
|
||||
}
|
||||
|
||||
|
||||
//////////////////////////////// Constraint Propagation ////////////////////////////////
|
||||
|
||||
/** Check if square s is consistent: that is, it has multiple possible values, or it has
|
||||
** one possible value which we can consistently fill. **/
|
||||
boolean arc_consistent(int[] grid, int s) {
|
||||
int count = NUM_DIGITS[grid[s]];
|
||||
return count >= 2 || (count == 1 && (fill(grid, s, grid[s]) != null));
|
||||
}
|
||||
|
||||
|
||||
/** After we eliminate d from possibilities for grid[s], check each unit of s
|
||||
** and make sure there is some position in the unit where d can go.
|
||||
** If there is only one possible place for d, fill it with d. **/
|
||||
boolean dual_consistent(int[] grid, int s, int d) {
|
||||
for (int[] u: UNITS[s]) {
|
||||
int dPlaces = 0; // The number of possible places for d within unit u
|
||||
int dplace = -1; // Try to find a place in the unit where d can go
|
||||
for (int s2: u) {
|
||||
if ((grid[s2] & d) > 0) { // s2 is a possible place for d
|
||||
dPlaces++;
|
||||
if (dPlaces > 1) break;
|
||||
dplace = s2;
|
||||
}
|
||||
}
|
||||
if (dPlaces == 0 || (dPlaces == 1 && (fill(grid, dplace, d) == null))) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
/** Look for two squares in a unit with the same two possible values, and no other values.
|
||||
** For example, if s and s2 both have the possible values 8|9, then we know that 8 and 9
|
||||
** must go in those two squares. We don't know which is which, but we can eliminate
|
||||
** 8 and 9 from any other square s3 that is in the unit. **/
|
||||
boolean naked_pairs(int[] grid, int s) {
|
||||
if (!runNakedPairs) { return true; }
|
||||
int val = grid[s];
|
||||
if (NUM_DIGITS[val] != 2) { return true; } // Doesn't apply
|
||||
for (int s2: PEERS[s]) {
|
||||
if (grid[s2] == val) {
|
||||
// s and s2 are a naked pair; find what unit(s) they share
|
||||
for (int[] u: UNITS[s]) {
|
||||
if (member(s2, u)) {
|
||||
for (int s3: u) { // s3 can't have either of the values in val (e.g. 8|9)
|
||||
if (s3 != s && s3 != s2) {
|
||||
int d = HIGHEST_DIGIT[val];
|
||||
int d2 = val - d;
|
||||
if (!eliminate(grid, s3, d) || !eliminate(grid, s3, d2)) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
|
||||
//////////////////////////////// Input ////////////////////////////////
|
||||
|
||||
/** The method `readFile` reads one puzzle per file line and returns a List of puzzle grids. **/
|
||||
List<int[]> readFile(String filename) throws IOException {
|
||||
BufferedReader in = new BufferedReader(new FileReader(filename));
|
||||
List<int[]> grids = new ArrayList<int[]>(1000);
|
||||
String gridstring;
|
||||
while ((gridstring = in.readLine()) != null) {
|
||||
grids.add(parseGrid(gridstring));
|
||||
if (reversePuzzle) {
|
||||
grids.add(parseGrid(new StringBuilder(gridstring).reverse().toString()));
|
||||
}
|
||||
}
|
||||
return grids;
|
||||
}
|
||||
|
||||
|
||||
/** Parse a gridstring into a puzzle grid: an int[] with values DIGITS[0-9] or ALL_DIGITS. **/
|
||||
int[] parseGrid(String gridstring) {
|
||||
int[] grid = new int[N * N];
|
||||
int s = 0;
|
||||
for (int i = 0; i<gridstring.length(); ++i) {
|
||||
char c = gridstring.charAt(i);
|
||||
if ('1' <= c && c <= '9') {
|
||||
grid[s++] = DIGITS[c - '1']; // A single-bit set to represent a digit
|
||||
} else if (c == '0' || c == '.') {
|
||||
grid[s++] = ALL_DIGITS; // Any digit is possible
|
||||
}
|
||||
}
|
||||
assert s == N * N;
|
||||
return grid;
|
||||
}
|
||||
|
||||
|
||||
/** Initialize a grid from a puzzle.
|
||||
** First initialize every square in the new grid to ALL_DIGITS, meaning any value is possible.
|
||||
** Then, call `fill` on the puzzle's filled squares to initiate constraint propagation. **/
|
||||
int[] initialize(int[] puzzle) {
|
||||
int[] grid = new int[N * N]; Arrays.fill(grid, ALL_DIGITS);
|
||||
for (int s: SQUARES) { if (puzzle[s] != ALL_DIGITS) { fill(grid, s, puzzle[s]); } }
|
||||
return grid;
|
||||
}
|
||||
|
||||
|
||||
//////////////////////////////// Output and Tests ////////////////////////////////
|
||||
|
||||
boolean headerPrinted = false;
|
||||
|
||||
/** Print stats on puzzles solved, average time, frequency, threads used, and name. **/
|
||||
void printStats(int nGrids, long startTime, String name) {
|
||||
double usecs = (System.nanoTime() - startTime) / 1000.;
|
||||
String line = String.format("%7d %6.1f %7.3f %7d %10.1f %s",
|
||||
nGrids, usecs / nGrids, 1000 * nGrids / usecs, nThreads, backtracks * 1. / nGrids, name);
|
||||
synchronized (this) { // So that printing from different threads doesn't get garbled
|
||||
if (!headerPrinted) {
|
||||
System.out.println("Puzzles μsec KHz Threads Backtracks Name\n"
|
||||
+ "======= ====== ======= ======= ========== ====");
|
||||
headerPrinted = true;
|
||||
}
|
||||
System.out.println(line);
|
||||
backtracks = 0;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
/** Print the original puzzle grid and the solution grid. **/
|
||||
void printGrids(String name, int[] puzzle, int[] solution) {
|
||||
String bar = "------+-------+------";
|
||||
String gap = " "; // Space between the puzzle grid and solution grid
|
||||
if (solution == null) solution = new int[N * N];
|
||||
synchronized (this) { // So that printing from different threads doesn't get garbled
|
||||
System.out.format("\n%-22s%s%s\n", name + ":", gap,
|
||||
(verify(solution, puzzle) ? "Solution:" : "FAILED:"));
|
||||
for (int r = 0; r < N; ++r) {
|
||||
System.out.println(rowString(puzzle, r) + gap + rowString(solution, r));
|
||||
if (r == 2 || r == 5) System.out.println(bar + gap + " " + bar);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
/** Return a String representing a row of this puzzle. **/
|
||||
String rowString(int[] grid, int r) {
|
||||
String row = "";
|
||||
for (int s = r * 9; s < (r + 1) * 9; ++s) {
|
||||
row += (char) ((NUM_DIGITS[grid[s]] == 9) ? '.' : (NUM_DIGITS[grid[s]] != 1) ? '?' :
|
||||
('1' + Integer.numberOfTrailingZeros(grid[s])));
|
||||
row += (s % 9 == 2 || s % 9 == 5 ? " | " : " ");
|
||||
}
|
||||
return row;
|
||||
}
|
||||
|
||||
|
||||
/** Unit Tests. Just getting started with these. **/
|
||||
void runUnitTests() {
|
||||
assert N == 9;
|
||||
assert SQUARES.length == 81;
|
||||
for (int s: SQUARES) {
|
||||
assert UNITS[s].length == 3;
|
||||
assert PEERS[s].length == 20;
|
||||
}
|
||||
assert Arrays.equals(PEERS[19],
|
||||
new int[] {18, 20, 21, 22, 23, 24, 25, 26, 1, 10, 28, 37, 46, 55, 64, 73, 0, 2, 9, 11});
|
||||
assert Arrays.deepToString(UNITS[19]).equals(
|
||||
"[[18, 19, 20, 21, 22, 23, 24, 25, 26], [1, 10, 19, 28, 37, 46, 55, 64, 73], [0, 1, 2, 9, 10, 11, 18, 19, 20]]");
|
||||
System.out.println("Unit tests pass.");
|
||||
}
|
||||
}
|
||||
1355
ipynb/SudokuJava.ipynb
Normal file
1355
ipynb/SudokuJava.ipynb
Normal file
File diff suppressed because one or more lines are too long
10
ipynb/hardest.txt
Normal file
10
ipynb/hardest.txt
Normal file
@@ -0,0 +1,10 @@
|
||||
85...24..72......9..4.........1.7..23.5...9...4...........8..7..17..........36.4.
|
||||
..53.....8......2..7..1.5..4....53...1..7...6..32...8..6.5....9..4....3......97..
|
||||
12..4......5.69.1...9...5.........7.7...52.9..3......2.9.6...5.4..9..8.1..3...9.4
|
||||
...57..3.1......2.7...234......8...4..7..4...49....6.5.42...3.....7..9....18.....
|
||||
1....7.9..3..2...8..96..5....53..9...1..8...26....4...3......1..4......7..7...3..
|
||||
1...34.8....8..5....4.6..21.18......3..1.2..6......81.52..7.9....6..9....9.64...2
|
||||
...92......68.3...19..7...623..4.1....1...7....8.3..297...8..91...5.72......64...
|
||||
.6.5.4.3.1...9...8.........9...5...6.4.6.2.7.7...4...5.........4...8...1.5.2.3.4.
|
||||
7.....4...2..7..8...3..8.799..5..3...6..2..9...1.97..6...3..9...3..4..6...9..1.35
|
||||
....7..2.8.......6.1.2.5...9.54....8.........3....85.1...3.2.8.4.......9.7..6....
|
||||
BIN
ipynb/map3.png
Normal file
BIN
ipynb/map3.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 47 KiB |
BIN
ipynb/map4.png
Normal file
BIN
ipynb/map4.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 136 KiB |
1
ipynb/one.txt
Normal file
1
ipynb/one.txt
Normal file
@@ -0,0 +1 @@
|
||||
..7........1....3..5..4.6...4....7...6...3........1..2.....7.......6..8...2.....1
|
||||
528
ipynb/risk.ipynb
528
ipynb/risk.ipynb
File diff suppressed because one or more lines are too long
500000
ipynb/sudata.txt
Normal file
500000
ipynb/sudata.txt
Normal file
File diff suppressed because it is too large
Load Diff
10000
ipynb/sudoku10k.txt
Normal file
10000
ipynb/sudoku10k.txt
Normal file
File diff suppressed because it is too large
Load Diff
10
ipynb/ten.txt
Normal file
10
ipynb/ten.txt
Normal file
@@ -0,0 +1,10 @@
|
||||
..7........1....3..5..4.6...4....7...6...3........1..2.....7.......6..8...2.....1
|
||||
..3..2.8.14......9.68.593.7..24.5...............2.85..9.457.86.6......75.8.6..4..
|
||||
.....4.....5.....3...8.1.6.......81..73........2..6.......2....14...........5...7
|
||||
......8..3...6.9.71.8.9..6..673...2....2.6....2...938..3..8.1.25.267...8..9......
|
||||
......7.4.1.5......6..........15.9..8.....3.....6.....4...97.....7..8..........1.
|
||||
..2..6..7......8.9.8..4..6.85.2..93.....3.....93..1.25.1..9..5.5.4......2..3..6..
|
||||
.....8......6.4.........1.7....9......5.....36......84..7.......4.....6.....269..
|
||||
....1......4....6....85............289............7.34.........15....8....3..4..7
|
||||
...9.........1..7..9...4.2..4.16.....5.3......1...7.533......1....58..4.8.....2..
|
||||
.......8...4....15..23.7........3...8.......1.....2..6........4....1.....26...7..
|
||||
48697
ipynb/usecs.txt
Normal file
48697
ipynb/usecs.txt
Normal file
File diff suppressed because it is too large
Load Diff
Reference in New Issue
Block a user