Table of contents
Sorting-Algorithms-Blender
Bubble Sort
Bubble sort is one of the most straightforward sorting algorithms. Its name comes from the way the algorithm works: With every new pass, the largest element in the list “bubbles up” toward its correct position.
Bubble sort consists of making multiple passes through a list, comparing elements one by one, and swapping adjacent items that are out of order.
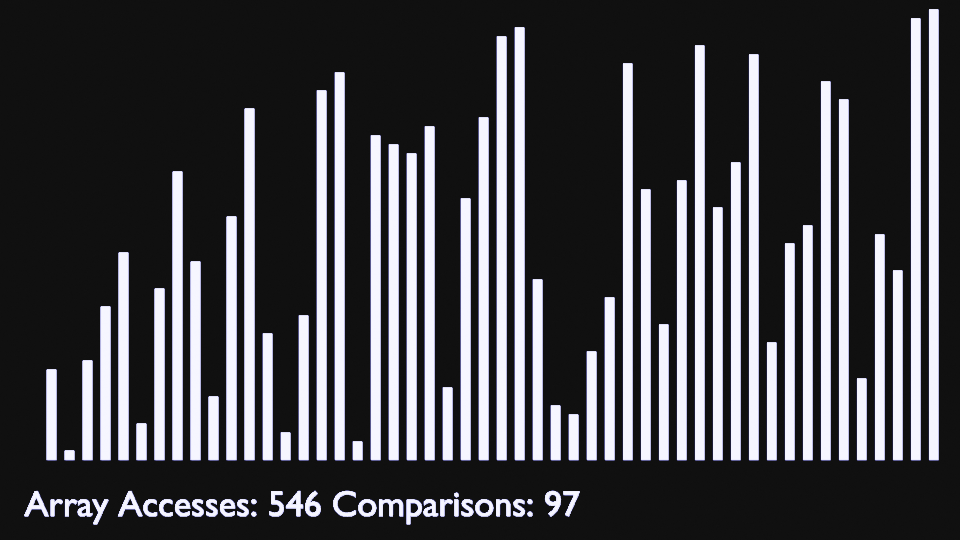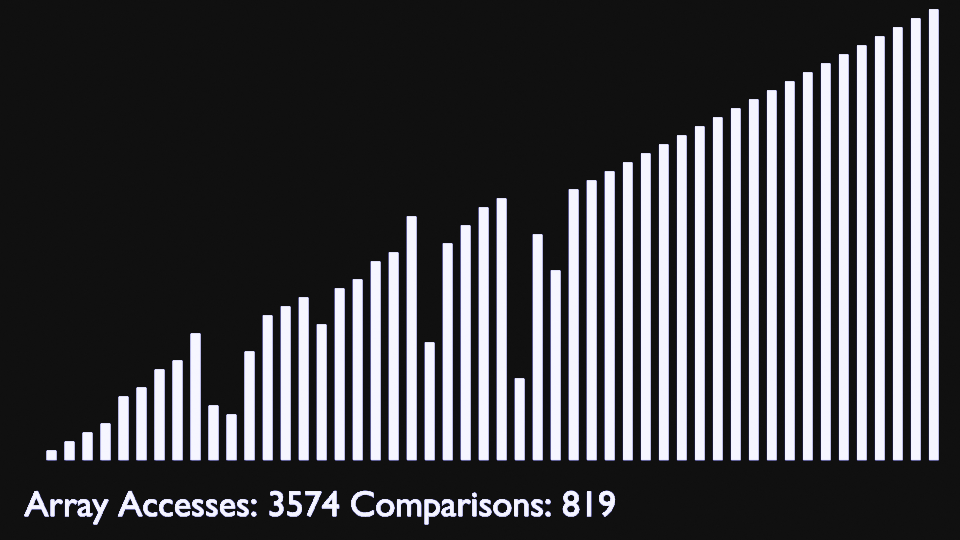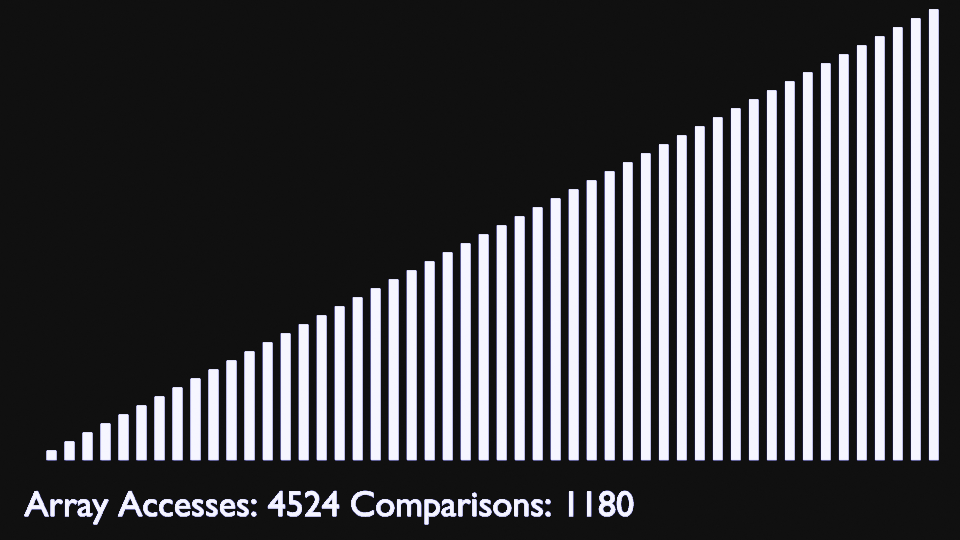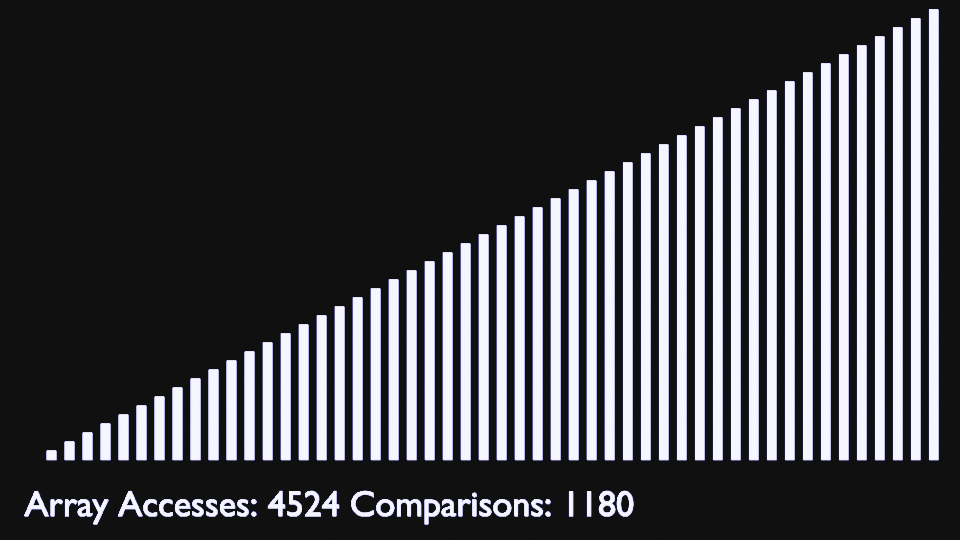
Insertion Sort
Like bubble sort, the insertion sort algorithm is straightforward to
implement and understand. But unlike bubble sort, it builds the sorted
list one element at a time by comparing each item with the rest of the
list and inserting it into its correct position. This “insertion”
procedure gives the algorithm its name. 
Selection Sort
The selection sort algorithm sorts an array by repeatedly finding the minimum element (considering ascending order) from unsorted part and putting it at the beginning. The algorithm maintains two subarrays in a given array.- The subarray which is already sorted.
- Remaining subarray which is unsorted.
In every iteration of selection sort, the minimum element (considering ascending order) from the unsorted subarray is picked and moved to the sorted subarray.
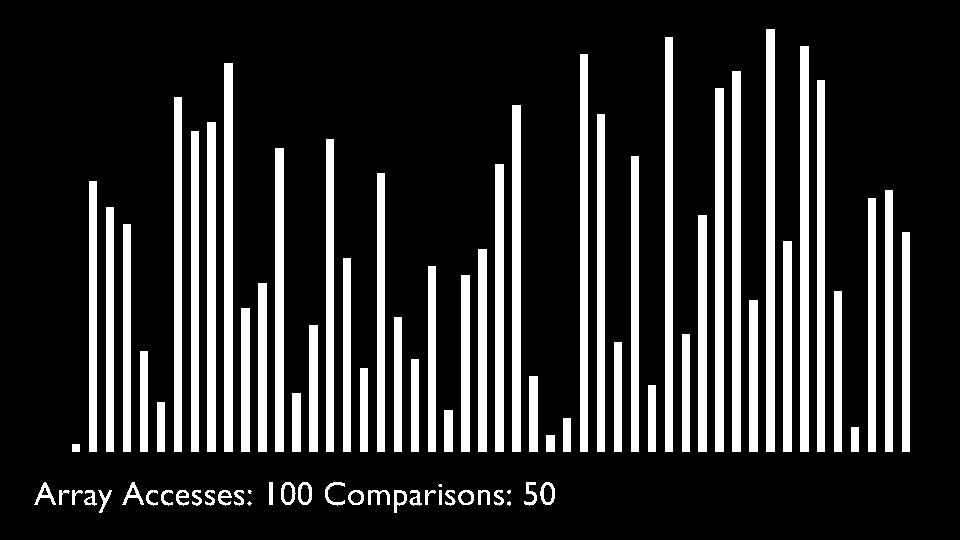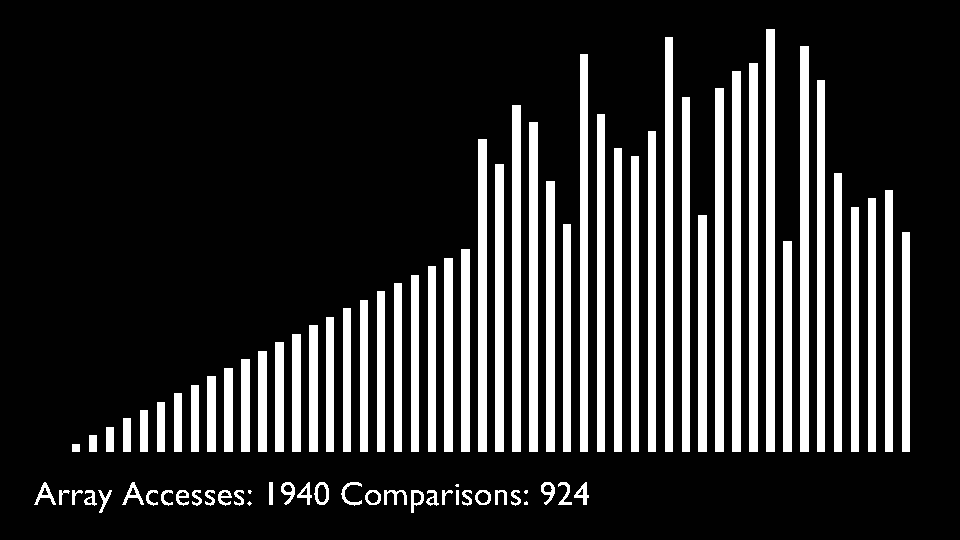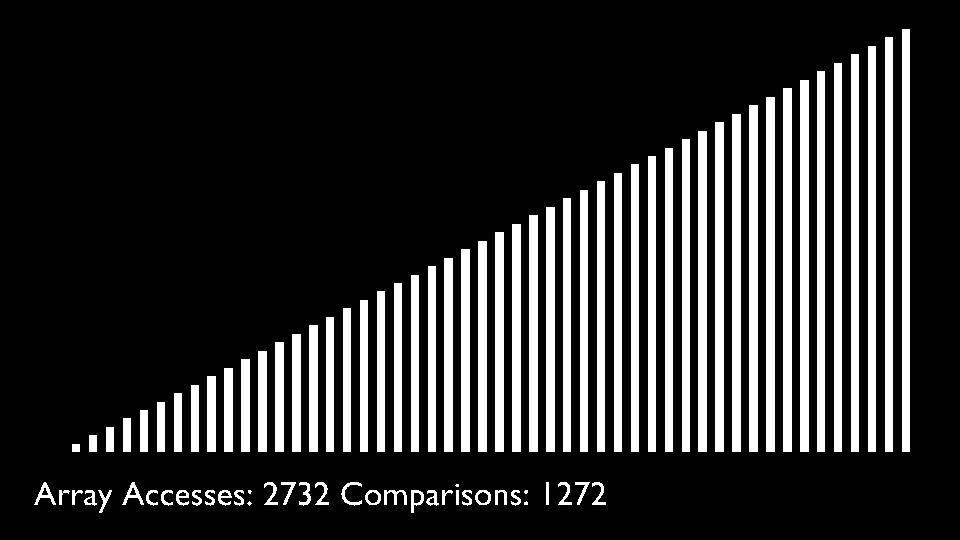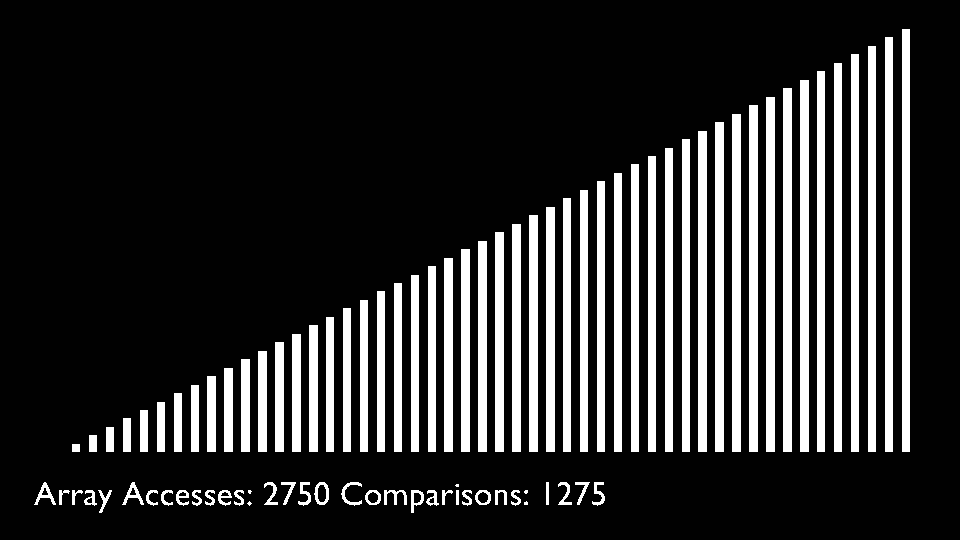
Shell Sort
The shell sort algorithm extends the insertion sort algorithm and is very efficient in sorting widely unsorted arrays. The array is divided into sub-arrays and then insertion sort is applied. The algorithm is:- Calculate the value of the gap.
- Divide the array into these sub-arrays.
- Apply the insertion sort.
- Repeat this process until the complete list is sorted.
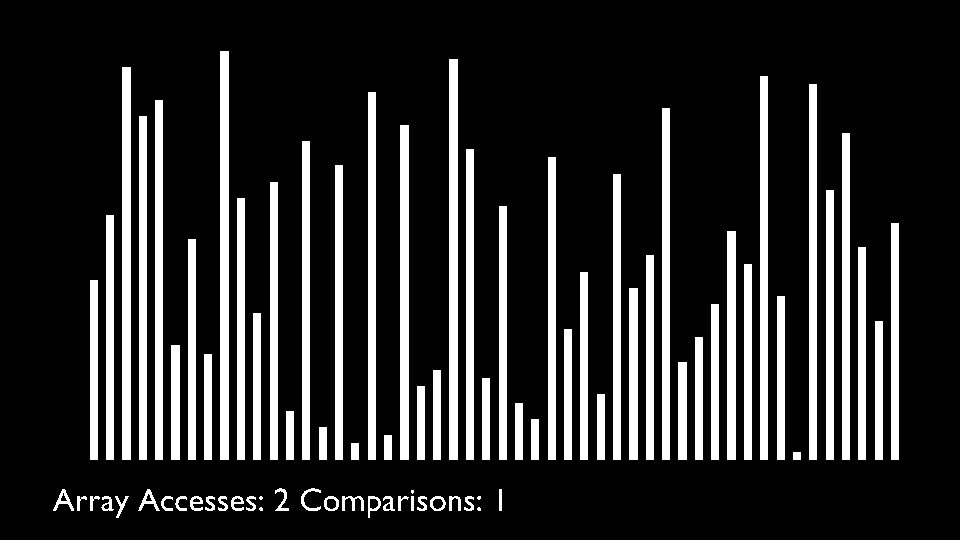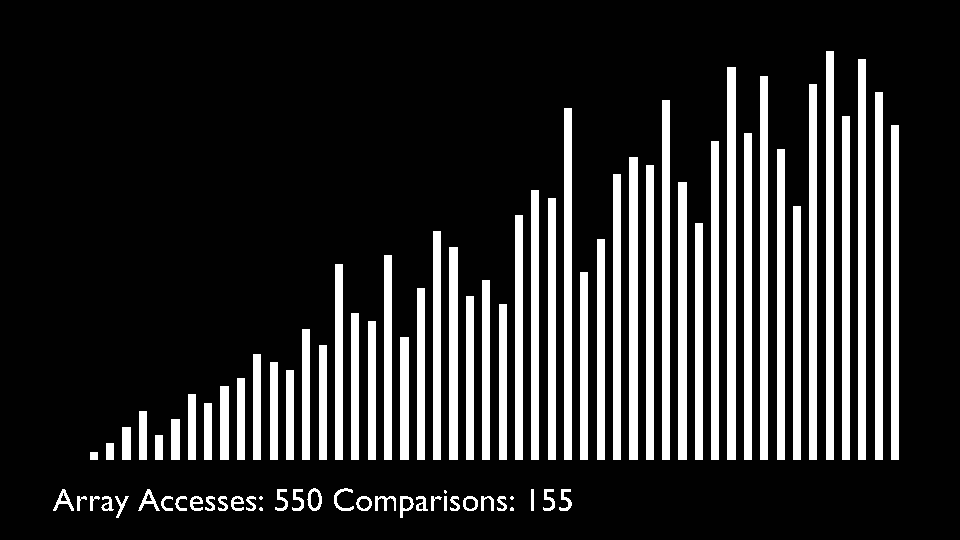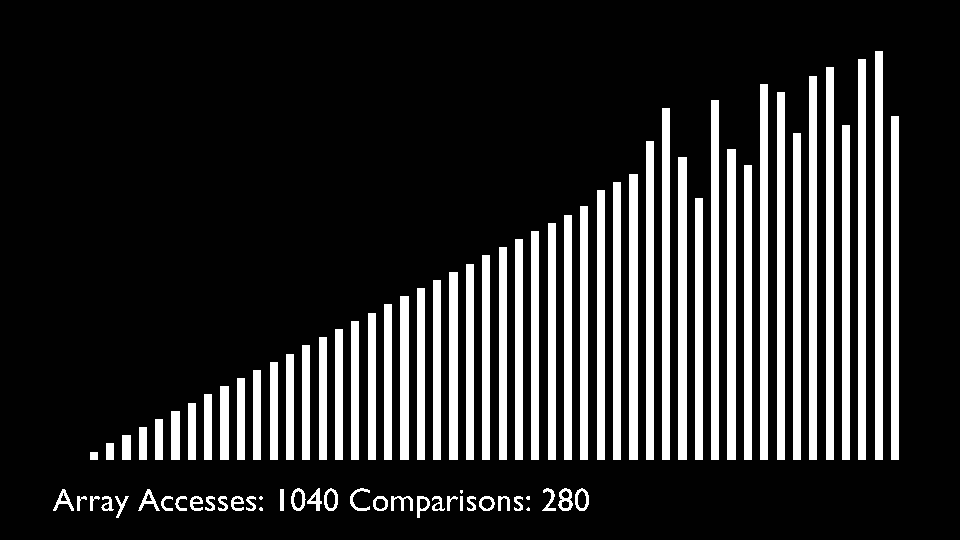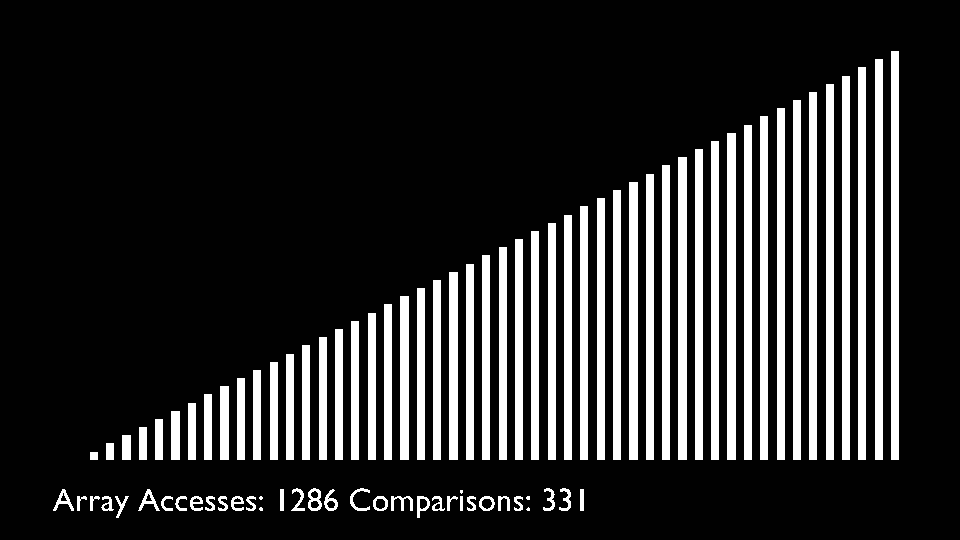
Merge Sort
Merge sort uses the divide and conquer approach to sort the elements. It is one of the most popular and efficient sorting algorithm. It divides the given list into two equal halves, calls itself for the two halves and then merges the two sorted halves. We have to define the merge() function to perform the merging.
The sub-lists are divided again and again into halves until the list cannot be divided further. Then we combine the pair of one element lists into two-element lists, sorting them in the process. The sorted two-element pairs is merged into the four-element lists, and so on until we get the sorted list.
Quick Sort
Like Merge Sort, QuickSort is a Divide and Conquer algorithm. It picks an element as pivot and partitions the given array around the picked pivot. There are many different versions of quickSort that pick pivot in different ways.- Always pick first element as pivot.
- Always pick last element as pivot.
- Pick a random element as pivot.
- Pick median as pivot. (implemented below)
The key process in quickSort is partition(). Target of partitions is, given an array and an element x of array as pivot, put x at its correct position in sorted array and put all smaller elements (smaller than x) before x, and put all greater elements (greater than x) after x. All this should be done in linear time.
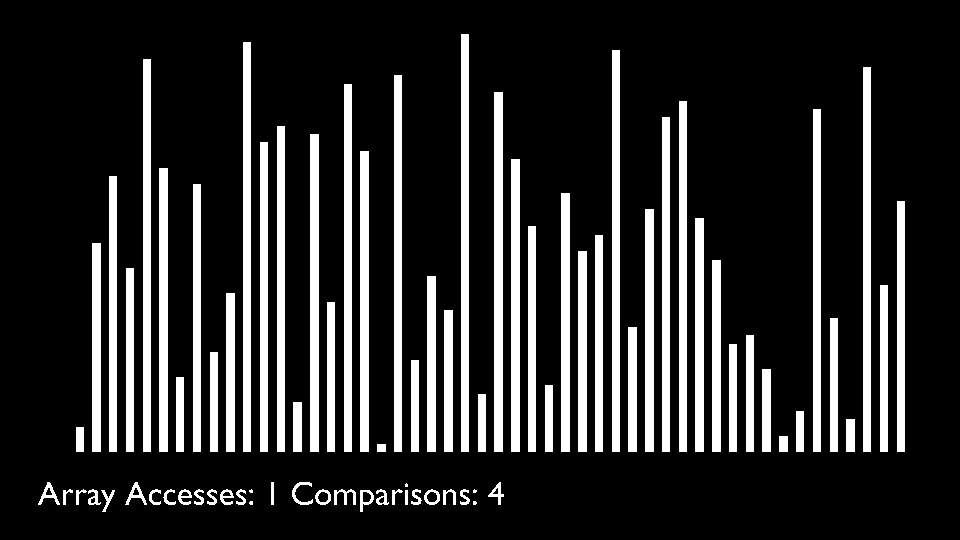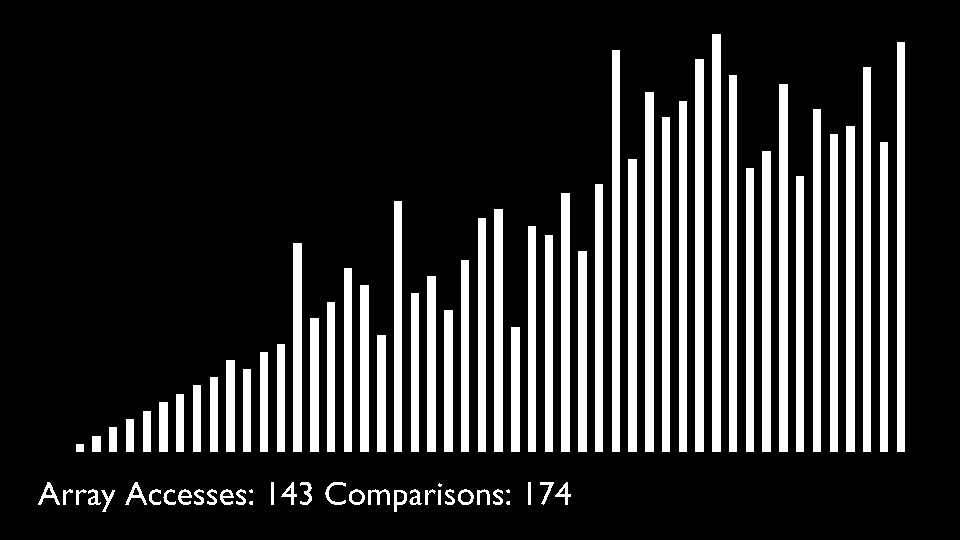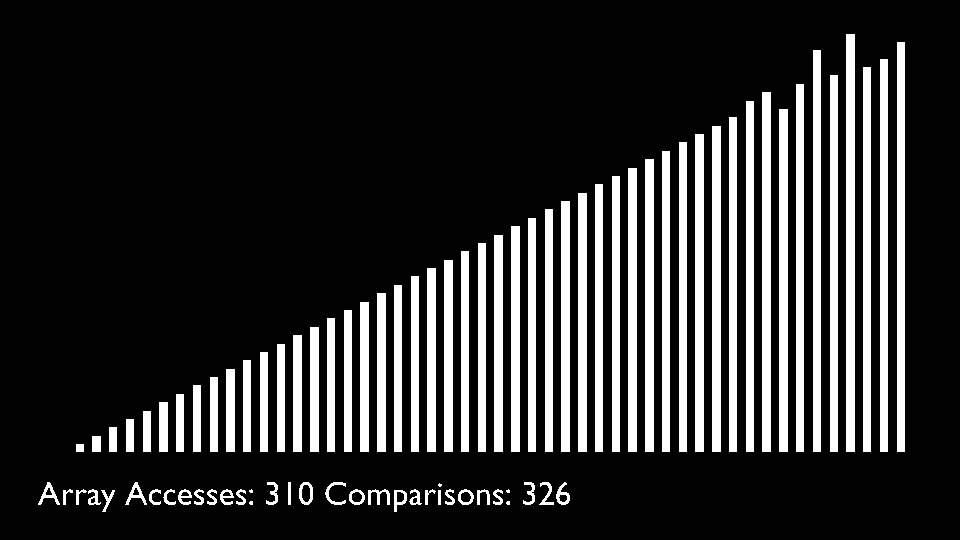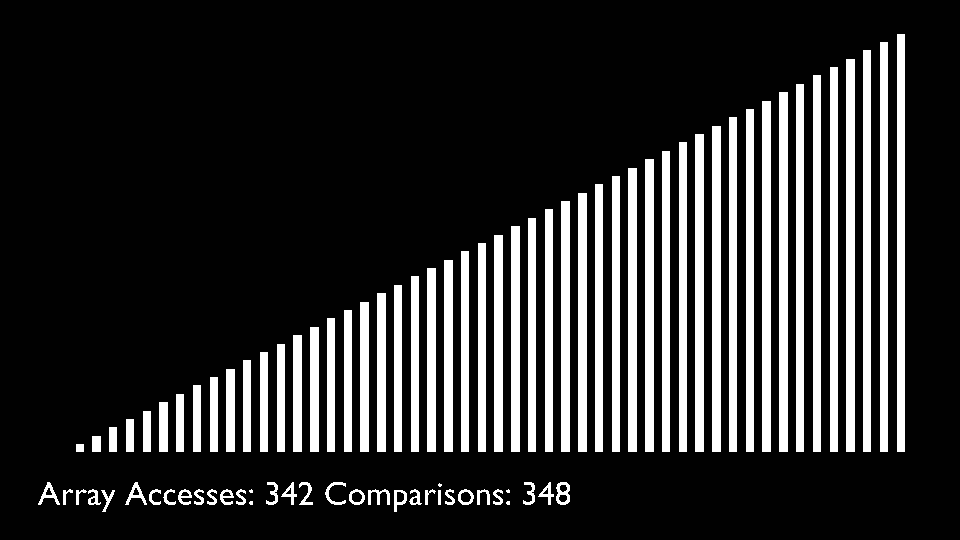
Big O
Big O notation is the language we use for talking about how long an algorithm takes to run. It’s how we compare the efficiency of different approaches to a problem. With Big O notation we express the runtime in terms of how quickly it grows relative to the input, as the input gets arbitrarily large.
Let’s break that down:-
how quickly the runtime grows
It’s hard to pin down the exact runtime of an algorithm. It depends on the speed of the processor, what else the computer is running, etc. So instead of talking about the runtime directly, we use big O notation to talk about how quickly the runtime grows. -
relative to the input
If we were measuring our runtime directly, we could express our speed in seconds. Since we’re measuring how quickly our runtime grows, we need to express our speed in terms of…something else. With Big O notation, we use the size of the input, which we call “n”. So we can say things like the runtime grows “on the order of the size of the input” (O(n)) or “on the order of the square of the size of the input” (O(n^2)). -
as the input gets arbitrarily
Our algorithm may have steps that seem expensive when “n” is small but are eclipsed eventually by other steps as “n” gets huge. For big O analysis, we care most about the stuff that grows fastest as the input grows, because everything else is quickly eclipsed as “n” gets very large. (If you know what an asymptote is, you might see why “big O analysis” is sometimes called “asymptotic analysis.”)
| Algorithm | Time Complexity | Space Complexity | ||
|---|---|---|---|---|
| Best Case | Average Case | Worst Case | Worst Case | |
| Quick Sort |
Ω(n
log(n))
|
Θ(n
log(n))
|
O(n^2)
|
O(log(n))
|
| Merge Sort |
Ω(n
log(n))
|
Θ(n
log(n))
|
O(n
log(n))
|
O(n)
|
| Tim Sort |
Ω(n)
|
Θ(n
log(n))
|
O(n
log(n))
|
O(n)
|
| Heap Sort |
Ω(n
log(n))
|
Θ(n
log(n))
|
O(n
log(n))
|
O(1)
|
| Bubble Sort |
Ω(n)
|
Θ(n^2)
|
O(n^2)
|
O(1)
|
| Insertion Sort |
Ω(n)
|
Θ(n^2)
|
O(n^2)
|
O(1)
|
| Selection Sort |
Ω(n^2)
|
Θ(n^2)
|
O(n^2)
|
O(1)
|
| Tree Sort |
Ω(n
log(n))
|
Θ(n
log(n))
|
O(n^2)
|
O(n)
|
| Shell Sort |
Ω(n
log(n))
|
Θ(n(log(n))^2)
|
O(n(log(n))^2)
|
O(1)
|
| Bucket Sort |
Ω(n+k)
|
Θ(n+k)
|
O(n^2)
|
O(n)
|
| Radix Sort |
Ω(nk)
|
Θ(nk)
|
O(nk)
|
O(n+k)
|
| Counting Sort |
Ω(n+k)
|
Θ(n+k)
|
O(n+k)
|
O(k)
|
| Cube Sort |
Ω(n)
|
Θ(n
log(n))
|
O(n
log(n))
|
O(n)
|